
A Video Interview with Mike Clark, Chief Architect of Zen at AMD


Today’s “article” is a little bit different to what you readers are used to.
This article is a transcript of our video interview I conducted with Mike Clark at AMD. This was my first video interview I have conducted and if you guys like this type of content, comment down below! Also feel free to comment down below with any improvements you guys would recommend moving forward.
The transcript below has been edited for readability and conciseness.
George Cozma: Hello, you fine Internet folks. I’m not a 2D name on a page. I’m a 3D person. My name is Cheese, also known in the 3D World as George Cozma from Chips and Cheese. We are here at the AMD Zen 5 Tech Day and with me I have the father of Zen, Mike Clark. Would you like to introduce yourself?
Mike Clark: Yeah, My name is Mike Clark. I’ve been working at AMD for 31 years on core, started on the K5, worked on pretty much every core since then. Father of Zen and in charge of the road map going forward.
George Cozma: So jumping right into Zen 5, starting with of course the front end. On your slides, you showed that the branch predictor could do two taken and two ahead branches. What are taken and ahead branches?
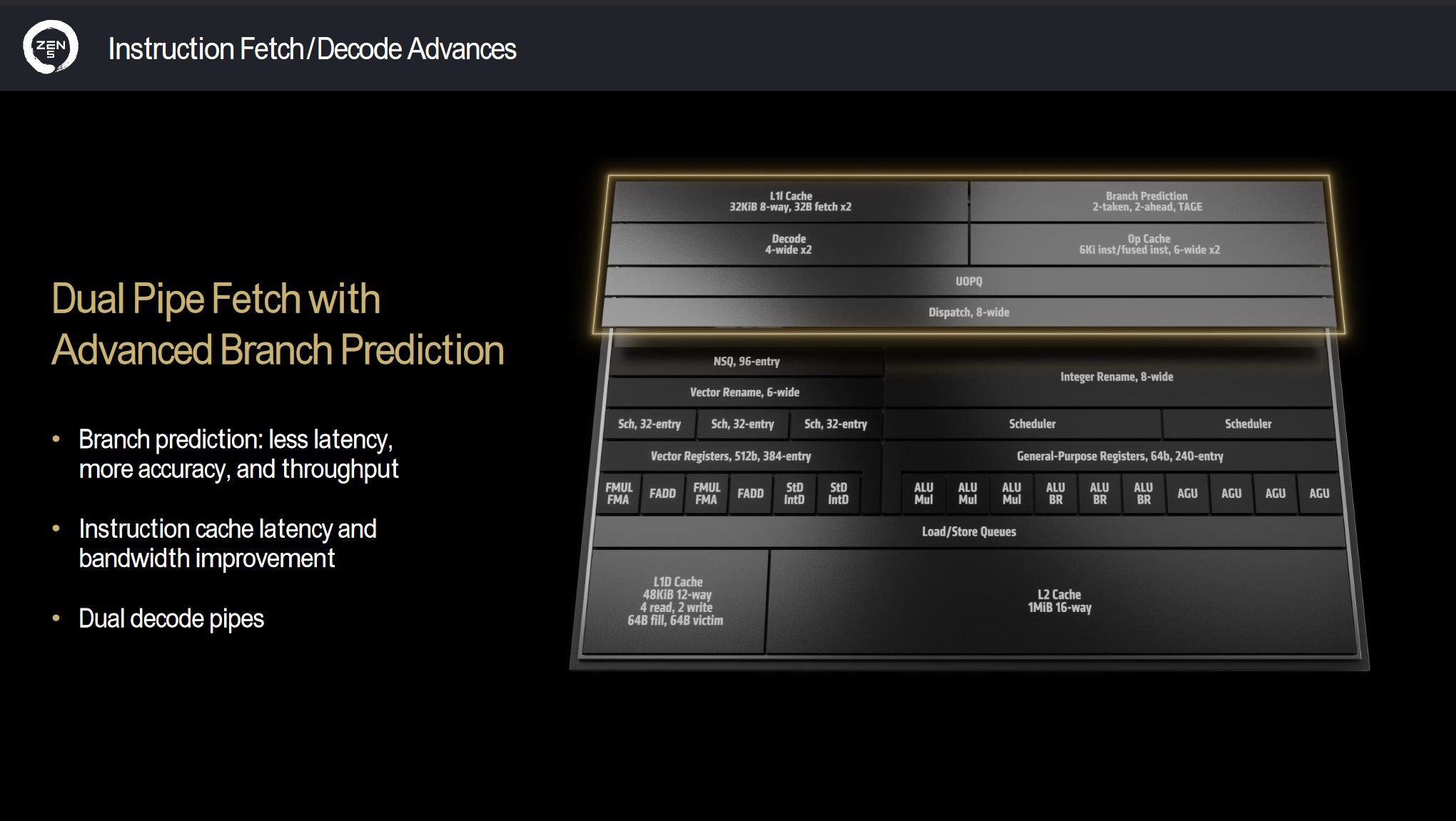
Mike Clark: Well, it’s more of your trying to look an extra step ahead of and so you can get ahead of the branch prediction flow and provide more predictions per cycle forward into the machine.
George Cozma: Can the branch predictor do two taken and two ahead branches in a cycle? Or is it 2 branches of total?
Mike Clark: I mean it’s complicated, there’s rules around when we can do 2 ahead. But yes, in general I would say yes.
George Cozma: So yes, to two branches per cycle, or yes to two ahead and two taken branches?
Mike Clark: We can, in certain situations, do both.
George Cozma: So moving from the branch predictor down a bit to the decoders, your diagrams show 2 by 4 wide decoders. Is that 2 independent clusters or are they sharing stuff like fetch?
Mike Clark: They get fed from the dual ported instruction fetch to feed the decoders. We do decode them then [and] we still do decode in order, and so they, but they from that point of view, each one knows the start of the packet to decode and is operating independently down that pipeline.
George Cozma: Now that brings me down to the micro-op cache. Again, in your diagrams you show 2 by 6 wide for the micro-op cache. Now in our conversations you have said that it’s a dual ported 6 wide op cache. What exactly does that mean for the throughput at any given time?
Mike Clark: So, it means that you know in in the best-case scenario we’re accessing the op cache with two fetch addresses and they both hit and we pull out the maximum we can pull out for any hit is 6 instructions and that if they both hit we can then deliver 12 instructions in one cycle out of the op cache.
Now we can’t always build 6 per entry. We don’t always hit or have them properly aligned so they can always hit in the op cache. So that’s why we actually, if you think about it, we’re 8 wide dispatch and be like, well, why would you grab 12 [ops] if you can only dispatch 8 [ops] but 12 [ops] is, you know the maximum and so it has to be a balance point that we pull more than we can, because sometimes we are inefficient and we can’t get all the instructions we want.
George Cozma: You know, for a single thread of it, let’s say you’re running a workload that only uses one thread on a given core. Can a single thread take advantage of all of the front-end resources and can it take advantage of both decode clusters and the entirety of the dual ported OP cache?
Mike Clark: The answer is yes, and it’s a great question to ask because I explain SMT to a lot of people, they come in with the notion that we don’t [and] they aren’t able to use all these resources when we’re in single threaded mode, but our design philosophy is that barring a few, very rare microarchitectural exceptions, everything that matters is available in one thread mode. If we imagine we are removing [SMT] it’s not like we’d go shrink anything. There’s nothing to shrink. This is what we need for good, strong single threaded performance. And we’ve already built that.
George Cozma: Now when both SMT threads are going, what parts of the core are statically partitioned versus competitively shared? Has that really changed from Zen 4 or is it still mostly the same?
Mike Clark: Well, one thing that has changed is with the double decoder when we are in two thread mode, we give a decoder to each thread. We didn’t even have that before, so we couldn’t do that but now we have it we do.
George Cozma: So, each thread basically gets a single 4 wide decoder to itself.
Mike Clark: Yeah, but I mean, they come back to your more base architecture question, which hasn’t changed much over there. Caches are competitively shared [and] the TLB’s are competitively shared. We have to tag them because you can’t use other threads, but you know the execution resource resources are all competitively shared. And then we do statically partitioned the retire queue, reorder buffer, store queue, the micro-op queue [all] gets statically partitioned. It’s not really a big performance thing.
So yeah, we and we kind of do those just because of the complexity of trying to deal with an out of order engine and trying to deal with the dynamic reorder buffer has been quite challenging so we never tried [to share those resources] and not really felt like there’s real performance there. There are a lot of other limitations and things we’ve [improved] over the years, I mean from Zen to Zen 5, we’ve continued to enhance SMT. Not from like I said, not from building structures bigger for SMT, but more from our watermarking in those [structures] though we competitively share them, there is some watermarking [to] reserve some of the resources [in the core].
If one thread has been stuck on a long delay, we don’t want the other thread to consume all the resources, then it wakes up and wants to go and it can’t go. So, we want to keep a burstiness to it, but we want to competitively share it too, because the two threads can be at quite different performance levels, and we don’t want to be the one that can use all the resources.
George Cozma: Oh absolutely. Now, you said you were talking about the reorder buffer [and] moving down the stack, Zen 5 now has an 8 wide dispatch feeding a 448-entry reorder buffer. Zen 4’ reorder buffer could merge micro-ops, can Zen 5’ do the same?

Mike Clark: We don’t support no op (NOP) fusion. We do have a lot of op fusion that’s similar, we still fuse branches and there’s some other cases that we fuse.
Part of the reason I would say we didn’t put let’s say no op fusion into Zen 5 is that we had that wider dispatch. Zen 1 to Zen 4 had that 6 wide dispatch and 4 ALUs, so getting the most out of that 6-wide dispatch was important and it drove some complexity into the dispatch interface to be able to do that. When looking at having the capability of an 8-wide dispatch and putting no op fusion on top of it, it didn’t really seem to pay off for the complexity because we had that wider dispatch natively. But you may see it come back. Zen 5 is sort of a foundational change to get to that 8-wide dispatch and 6 ALUs. We’re now going to try to optimize that pinch point of the architecture to get more and more out of it and so you know as we move forward, no op fusion is likely to come back as a good leverage of that eight wide dispatch. But for the first generation, we didn’t want to bite off the complexity.
George Cozma: Speaking of those, [Zen 5 is] now 6 ALUs why the move from 4 to 6? What was the reason for that?
Mike Clark: Yeah, as we think of Zen 5 we needed a new foundation for more compute to drive future workloads that continue to stay on this cadence of double digit IPC per generation. So you know we have been at the original Zen was 4-wide [dispatch and] 6 ALU’s and we had done a lot of innovation to really you know leverage all those resources [in] Zen, Zen 2, Zen 3, Zen 4. But we really we’re not to be able to keep that up, so we really needed to reset that foundation of a wider unit, more ALUs, more multiplies, more branch units, and then be able to leverage that like we did with the originals then to provide innovation going forward.
Another key point I’d like to hit on is it’s also hard for software trying to leverage, let’s say something that has 6 ALUs and 8-wide dispatch, they don’t get the payback when they run it on our older architecture. So even if they’re you know trying to tune their code and building smarter algorithms, there’s no payback for them so they don’t end up doing it. Whereas now that we’ve built it, they’ll start innovating on the software side with it [and they’ll go], “Holy cow look what I can do, I’ll do this, and I can do that” and you’ll see the actual foundational lift play out in the future on Zen 6 even though it was really Zen 5 that set the table for that and let software innovate.

George Cozma: Now, speaking of the integer side, you guys consolidate your schedulers so now you have one scheduler for the ALUs and one scheduler for the AGUs. Some insight into why you decided to merge those schedulers?
Mike Clark: Scheduling in our microarchitectures continues to evolve. Zen 2 had a shared AGU scheduler. We’ve mixed ALU and AGU queues together and scheduled out of them to get efficiency. With Zen 5, and we went to those six ALUs and if you look at Zen 4 we had a queue and a scheduler per ALU unit and so at dispatch, we had to pick which ops to send them.
As the out of order engine runs it resolves, you might have in one queue that you picked 3 ops become ready because the results came back but you can only issue one per ALU. So now you created a false latency in there and so and going to those six ALUs, it was only making it worse. So, we decided to go for a more unified scheduler where the ops first come into that then as they become ready, we pick the queue that they go to and we can afford and avoid those hazards that come up if we haven’t picked the right queue statically at dispatch time.
George Cozma: Now what’s interesting is now on the vector side, you’ve added a scheduler. You now have three schedulers along with bigger schedulers and NSQ (non-scheduling queue). Why did you add that third scheduler on the floating-point unit when you reduced the number of schedulers you had on the integer unit?

Mike Clark: So, it’s definitely an interesting area of the microarchitecture, but one fundamental thing is you know the [Integer] ALUs are pretty simple. Most of the ops are one cycle. You know we have multiplies and divides, but those [are not very common]. When you have to schedule multiple cycle ops [quite often], that makes the scheduler more complicated and so trying to also then unify that and be able to deal with the multiple latency ops as well as the different pipelines you know to try to grow that capacity we decided we needed to divide up the problem so we could [increase] the floating point ops that we could dispatch and have them in flight to grow into that window.
George Cozma: Speaking of latency and increased window size. Zen 5 has doubled the number of registers that the vector unit has access to, 384 from 192. Yet the integer side has only increased by 16 registers. Why the difference?
Mike Clark: I mean, it’s just a function of the register file is one of the pinch points really being able as we’ve gone to six ALUs as well and the AGUs. Being able to read and write that many registers that you might need to dispatch at one time is one of the critical paths in the design, and so you know it’s a slightly different again on the integer side where you have single cycle ops and so there’s a lot more pressure on that as well. Whereas on the floating-point side when you have longer latency ops, you have more time to sort of know how the registers are going to be needed and the algorithms tend to be more regular and loop based and on the integer side you have more branchy and more scatterbrain to use of registers. You have a lot more regularity on the floating-point side in general.
George Cozma: We were speaking earlier. Can you sort of explain the loaded store unit of Zen 5? I know I had some confusion about the number of loads and stores for both sides. Could you talk about that a bit?

Mike Clark: Yeah, so I’ll try, I mean I know it is a little bit complex. So, we like to think about it of the data cache can handle 4 memory operations per cycle and so starting from that baseline on the load side, they can all be loads, 4 loads, we can do. Now based on the size of the load, because we only have a data path to the floating-point unit that’s you know 512 bits on two of the ports. You can only do 2 loads that are floating point.
George Cozma: And that’s [the same for] 128-bit, 256-bit and 512-bit?
Mike Clark: Yeah, that same interface. Yeah. There’s only if you think about the physical bus routing, there’s just two floating point load ports. That’s all we have. Does that make sense?
George Cozma: Yep, and you can do two stores per cycle of any size.
Mike Clark: You can use two stores per cycle of any size.
Correction: Mike Clark reached out after the interview to correct this, Zen 5 is capable of 2 128b or 256b stores but only 1 512b store per cycle.
George Cozma: And of course, the most important question that I will ask you of the day, what is your favorite type of cheese?
Mike Clark: I would have to say cheddar.
George Cozma: Well, that concludes our first interview. I would like to thank you Mike Clark.
Mike Clark: Those are great questions. I love really getting into the meat of the architectures, it was great.
George Cozma: Well, if you want to know more about Zen 5, we will have an article about it at chipsandcheese.com [when we get the chips in for review]. If you like what we do, subscribe to our Patreon or throw us a few bucks on PayPal, and if you like this sort of interview style, then hit the like button and potentially subscribe for more.
Have a good one y’all!
Mike Clark: Thanks for having me.