
The Snapdragon X Elite’s Adreno iGPU

Qualcomm is no stranger to integrated graphics. Their Adreno GPU line has served through many generations of Snapdragon cell phone SoCs. But Qualcomm was never content to stay within the cell phone market, and harbored ambitions to move into higher power and higher performance brackets. Today, their Snapdragon X Elite takes aim at the laptop market. Adreno gets dragged along with it into a higher performance market that includes competitors like Intel’s Xe-LPG iGPU in Meteor Lake, or AMD’s RDNA 3 iGPU in Phoenix.
Officially, Qualcomm refers to the Snapdragon X Elite’s iGPU as Adreno X1. It’s a clean marketing name that breaks from the Adreno nxx naming convention of the past. With that past naming scheme, n would represent the architecture generation and larger values of xx would indicate larger implementations within that generation. Qualcomm may still use that naming scheme internally, since their drivers refer to the GPU as the Adreno 741. Adreno 741 suggests the Snapdragon X Elite’s iGPU is a scaled out version of the Adreno 730 previously tested in the Snapdragon 8+ Gen 1 cell phone chip.

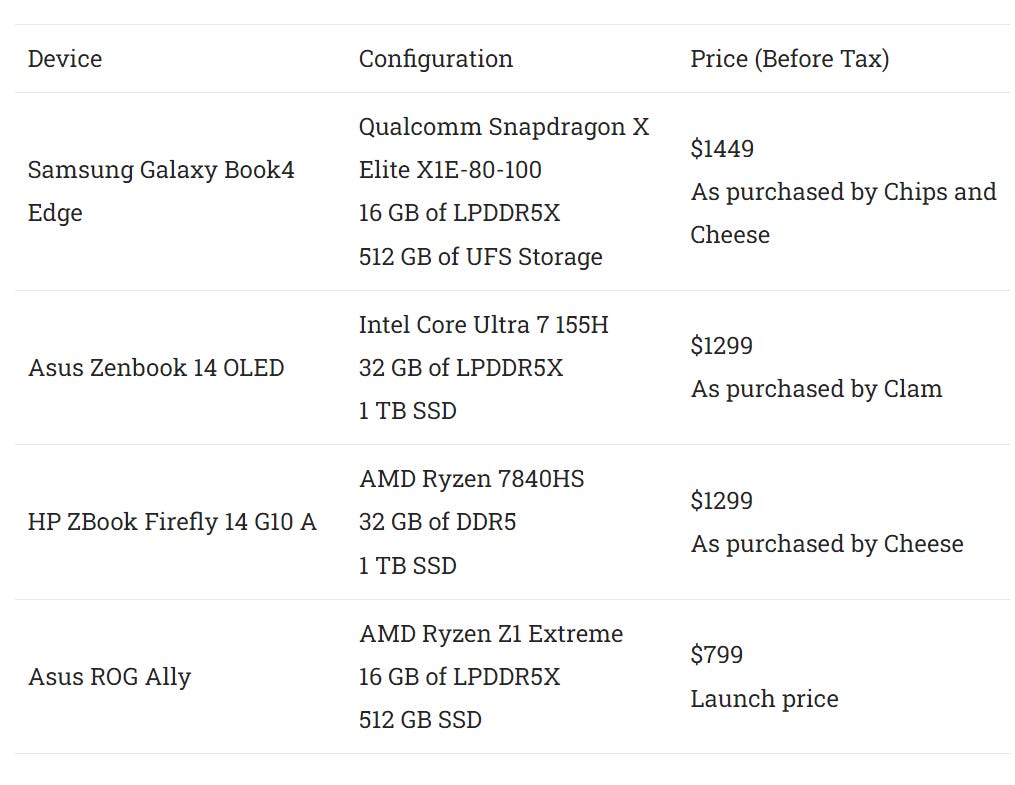
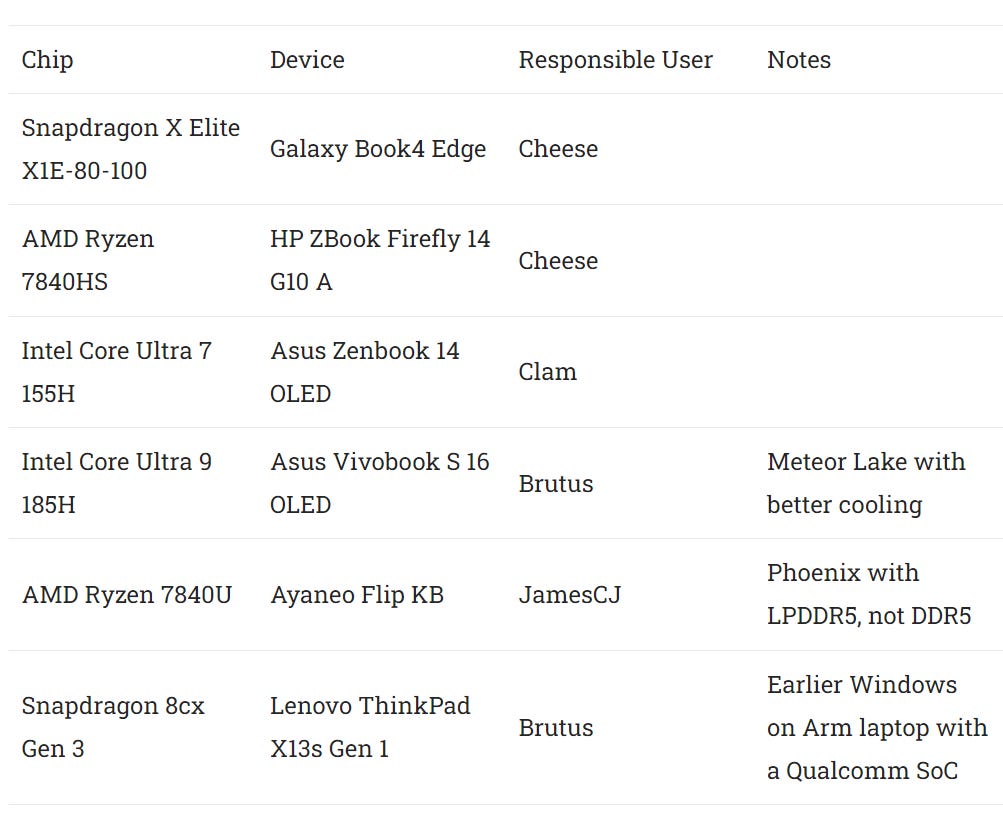
We’ll be using Adreno X1 to refer to the Snapdragon X Elite’s GPU for simplicity. Testing was performed on the Samsung Galaxy Book4 Edge. For comparison data, Intel’s Core Ultra 7 155H Meteor Lake chip was tested in the Asus Zenbook 14. AMD’s Phoenix was tested in a couple different configurations. The Ryzen Z1 Extreme was tested in the ROG Ally, and the Ryzen 7840HS was tested in the HP ZBook Firefly 14 G10 A.
To dive deep into each company’s respective GPU architectures, we’ll be using a mix of OpenCL tests written by Clam along with Vulkan-based tests written by Nemes. The latter is useful here as Qualcomm’s OpenCL implementation on Windows can be problematic at times. Credit also goes to other sites for reminding me to aggressively watermark images.
Acknowledgments
We would like to thank all of our Patreon members and Paypal donators who without which we would not be able to purchase the Samsung Galaxy Book4 Edge 16 inch Laptop that we have used to gather the data for this article. Without you folks, this article would not be possible so a massive thank you to you all.
Overview
Qualcomm aims to take on more demanding PC games by scaling out their Adreno 7xx architecture and clocking it higher. Adreno X1 can clock up to 1.5 GHz in the highest end Snapdragon X Elite SKUs, though it’s restricted to 1.25 GHz in the SKU we’re testing. 1.25 GHz is still much higher than the 900 MHz that Adreno 730 ran at in the Snapdragon 8+ Gen 1.

Beyond making the GPU bigger and faster, Qualcomm has enhanced various parts of the memory subsystem to keep the GPU fed. Caches are larger and enjoy improved bandwidth. There’s a new mid-level cluster cache, creating a four level cache setup. All that gets fed with a 128-bit LPDDR5X memory controller supporting up to 64 GB of DRAM capacity.

Intel Meteor Lake’s Xe-LPG iGPU has a simpler two-level cache hierarchy, but has more cache capacity at each level. While Adreno X1 is a comparatively wide iGPU with 1536 FP32 units, Meteor lake takes its 1024 FP32 units and clocks 50% higher. Theoretical FP32 throughput ends up being very close to Adreno X1’s.

Adreno X1’s Shader Processor
Adreno is built from Shader Processors (SPs), each of which contain two Micro Shader Processor Texture Processors (uSPTPs). A uSPTP can be best compared to the Compute Unit (CU) subdivision on AMD’s RDNA line. Both have their own texture units, a texture cache, and are further subdivided into two scheduler partitions. That makes a SP very similar in layout to a RDNA WGP, or Workgroup Processor. It’s also similar to Nvidia’s Streaming Multiprocessor as implemented in Maxwell and Pascal.

Qualcomm’s older Adreno 730 organizes execution units the same way. Each scheduler partition gets a 64-wide FP32 unit and can execute FP16 operations at double rate. Eight special function units handle complex operations like inverse square roots.

GPUs keep these execution units fed with a combination of wide vectors and thread level parallelism. Adreno X1 uses large 64-wide or 128-wide vectors (waves). AMD’s RDNA GPUs can use wave32 or wave64, while Nvidia sticks to wave32. Intel supports variable wave sizes up to wave32. Larger wave sizes let the GPU track more work in the equivalent of a single thread, but are more prone to losing throughput from divergence penalties. From microbenchmarking such divergence penalties, the older Adreno 730 appears to have a wave64 mode.

Large wave sizes increase pressure on register file capacity too. Each register allocated by the compiler takes up a wave-wide portion of the register file. One way to think of it is that shader programs are invoked in batches of 64 or 128 on Adreno X1. What looks like a 32-bit variable in a shader program would map to 64 or 128 32-bit values, each of which holds the variable’s value for one invocation of that shader program. Register file capacity is dynamically allocated depending on how many registers a shader program needs. If the compiler needs to allocate a lot of registers for a complex shader program, register file capacity could limit how many batches of shader invocations can be active at a time.

Qualcomm did not disclose Adreno X1’s maximum occupancy, or how many waves the scheduler can track. However, they do indicate each uSPTP has 192 KB of register file capacity. Each of the uSPTP’s two scheduler partitions would have 96 KB of registers. Mesa code indicates Adreno 730 had 64 KB of registers per scheduler partition, so Qualcomm increased register file capacity by 50%.

Even with the larger register file, Adreno X1 might struggle to hide latency with shaders that use a lot of registers. Even the low end variant of RDNA 3 has 128 KB register files. Nvidia does have smaller 64 KB register files on Pascal, Ampere, and Ada, but their smaller wave32 vectors let them get comparable occupancy to RDNA 3 in wave64 mode.
Intel does not dynamically allocate register file capacity. Each Xe Vector Engine has a 32 KB register file and always maxes out at eight in-flight waves. Each wave gets 4 KB of registers, which can be treated as 128 wave8 registers, 32 wave32 registers, or many other combinations depending on the compiler’s mood.

Adreno X1’s compute throughput is very competitive against Intel’s Meteor Lake iGPU. Qualcomm clocks lower, but makes up for it with very wide execution units. However, Meteor Lake does pull a lead for complex operations like inverse square roots. AMD’s Phoenix takes an all-of-the-above approach. It clocks high, has lots of FP32 units fed through dual issue or wave64 mode, and has six WGPs. AMD therefore gets a huge lead for FP32 throughput, and a smaller one in other places. Qualcomm however can keep pace for FP16, thanks to double rate FP16 execution. FP64 is not supported on Qualcomm hardware, so that’s omitted from the graph above.

Integer operations can be very common as well. Adreno X1 performs poorly with basic INT32 adds. Adreno 730 did fine with INT32 adds when tested through OpenCL, so I’m not sure what’s going on with Vulkan. Qualcomm does reasonably well for more complicated INT32 operations like multiplies and remainders. INT64 performance on Adreno X1 ranges from mediocre to exceptionally poor.
Cache and Memory Access
DRAM performance hasn’t been keeping up with advances in compute performance, and that holds true for GPUs as well as CPUs. Integrated GPUs can’t fit as much compute as their discrete counterparts due to power and thermal restrictions, but they still need competent cache setups to maintain good performance.

Memory accesses on Adreno X1 first check a 2 KB texture cache private to each uSPTP. Older Adreno GPUs had 1 KB texture caches going back to the Adreno 330 of 2013. On one hand, Qualcomm deserves credit for doubling L1 cache capacity. On the other, they still have the smallest L1 cache around. Latency is slightly worse than the much larger first level caches on RDNA 3 and Intel’s Xe-LPG.

First level cache bandwidth on Adreno X1 is just below 1 TB/s, putting it just short of Nvidia’s GTX 1050 3 GB. Recent iGPUs enjoy much more bandwidth from their L1 caches. To Qualcomm’s Credit, the Adreno X1 is a healthy improvement over the Adreno 730.

In Adreno tradition, Adreno X1’s first level cache is a dedicated texture cache. Compute accesses bypass the L1 and go to the next level in the cache hierarchy. It’s quite different from current AMD, Nvidia, and Intel GPU architectures, which have a general purpose first level cache with significant capacity. On prior Adreno generations, the GPU-wide L2 cache would have to absorb all compute accesses. Adreno X1 takes some pressure off the L2 by adding 128 KB cluster caches.

Superficially, the cluster cache feels like the L1 mid-level cache on AMD’s RDNA line. Both are shared across a cluster of GPU cores. However, Adreno X1’s cluster caches play a more crucial role because RDNA 3 has better caching in front of its 256 KB L1 caches. From OpenCL, pointer chasing within the cluster cache takes 56.62 ns of latency. Access latency is better than Vulkan’s 67 ns, likely because no time is wasted checking the 2 KB texture cache. Qualcomm’s cluster cache has comparable latency to AMD’s L1 cache.

However, I would have liked to see better performance from the cluster cache because it’ll serve more traffic than AMD’s L1. The L1 cache on RDNA 3 also has twice as much capacity.

Qualcomm does have three cluster cache instances across the Adreno X1 for a total capacity of 384 KB to AMD’s 512 KB of L1 capacity. Perhaps Qualcomm thought it would be easier to meet bandwidth demands with three cluster cache instances instead of two. However, bandwidth as measured from Vulkan is quite poor compared to AMD and Intel’s iGPUs. Curiously, test sizes that fit within the cluster cache don’t show higher bandwidth than the L2 cache.

AMD’s Phoenix and Intel’s Meteor Lake in comparison enjoy very high cache bandwidth. AMD and Intel’s bandwidth lead is so extreme that their measured L2 bandwidth exceeds Adreno X1’s L1 texture cache bandwidth. Qualcomm does have an advantage at larger test sizes thanks to a 6 MB System Level Cache (SLC). The SLC offers about 211 GB/s of bandwidth.

For accesses that aren’t cache friendly, Qualcomm benefits from very fast LPDDR5X. The Snapdragon X Elite has more theoretical bandwidth on tap than any other chip tested here. Test results show that too, with a 12.3% bandwidth advantage over Meteor Lake.

Cell phone chips traditionally had very tight memory bandwidth limitations. Even when OEMs were willing to get fast memory chips, low bus width meant available bandwidth was often far lower than on laptops. Snapdragon X Elite’s 128-bit memory bus flips that around. Qualcomm now finds themselves with a slight bandwidth lead over its rivals.
Local Memory (GMEM)
Adreno is built for tiled rendering. The screen is split into tiles. Hardware determines which primitives are visible in each tile and writes that “visibility stream” information to memory. Then, the screen is rendered one tlie at a time. Each tile’s render target fits within dedicated on-chip memory, called GMEM. By rendering to GMEM, Adreno avoids polluting the cache hierarchy and reduces memory bandwidth usage. It’s great for the traditional rasterization pipeline, especially on a shoestring power and memory bandwidth budget. GMEM doesn’t need tag and state arrays like a regular cache, so it takes less power and area to implement than an equivalently sized cache.

Unfortunately, tiled rendering isn’t applicable with compute or raytracing because primitive info isn’t directly exposed to the hardware. Adreno X1 has a rather large 3 MB block of GMEM, compared to Adreno 730’s already substantial 2 MB GMEM block. Leaving that block of memory unused for compute or raytracing kernels would be a waste. Qualcomm can therefore reuse GMEM for local memory or color/depth caches.

As local memory, GMEM enjoys very good latency characteristics. Latency is only slightly higher than on AMD and Intel’s current iGPUs. It’s also similar to the Snapdragon 8+ Gen 1’s Adreno 730. Perhaps Qualcomm allocated local memory out of GMEM all along, but I have no way to tell from software.

AMD, Intel, and Nvidia in contrast implement local memory with fast storage placed within their respective GPU cores. Intel allocates local memory out of a Xe Core’s L1 cache, much like Nvidia’s Ampere and Ada architectures. AMD backs local memory with a 128 KB Local Data Share in each RDNA WGP.

Those architectures have better local memory latency than Qualcomm does, but the difference is minor. It’s not like older Intel iGPUs that had much higher latency when accessing local memory carved out of L3 cache slices. Despite these differences, all of these architectures enjoy similar benefits when programmers can leverage local memory. Caches need to maintain tag and state arrays that indicate what portion of main memory is held in the cache’s data arrays. Access to main memory through the cache hierarchy have to go through address translation, because GPUs support multitasking just like CPUs. Finally, local memory can be accessed with fewer address bits because it’s much smaller than main memory.

Adreno X1 suffers similar local memory allocation restrictions to Adreno 730. A kernel can use up to 32 KB of local memory. The GPU as a whole can only have 384 KB of local memory allocated at a time. Try to allocate more, and some workgroups won’t be able to launch in parallel. I wonder if that’s because each uSPTP accesses local memory by sending a 15-bit address. AMD’s 128 KB LDS would require 17-bit addressing.
Besides guaranteed low latency, local memory offers high bandwidth because data’s guaranteed to be in on-chip SRAM. Qualcomm indicates GMEM can provide over 2 TB/s of bandwidth, but I can’t achieve anything near that when reading from local memory.

Achieved bandwidth with float4 loads is similar to L1 texture cache bandwidth, which puts it much lower than what AMD and Intel can achieve. Adreno X1 is closer to an older low end discrete GPU from Nvidia, but even that pulls a notable 45.2% lead.

I suspect my local memory bandwidth test is limited by how much data each SP can consume through its load/store subsystem, rather than how much bandwidth GMEM can provide. Bandwidth per SP clock is very close to 128 bytes per cycle on both Adreno X1 and Adreno 730. If each SP can indeed only pull in 128 bytes per cycle, even Qualcomm’s higher end 1.5 GHz version of the Adreno X1 would be capped at 1152 GB/s of local memory bandwidth. Perhaps Qualcomm’s 2 TB/s figure can be achieved if the ROPs access GMEM at the same time. I don’t have a way to test that though.
Atomics
Atomic operations let different threads exchange data. OpenCL allows atomic operations on both local and global memory. Atomics backed by local memory are often faster, but can only exchange data between threads running in the same workgroup. Adreno X1 does a passable job local memory atomics and improves over Adreno 730. However, AMD and Intel’s iGPUs can handle atomics even faster, likely because their local memory sits closer to the execution units.

Global memory atomics can work between any pair of threads running on the GPU. Again, Adreno X1 improves over older Adreno generations. Performance is much better than on the Adreno 730.

This time, Qualcomm’s performance is close to AMD and Intel’s. All GPUs here are likely handling cross thread communication through the L2 cache.
FluidX3D
FluidX3D uses the lattice Boltzmann method to simulate fluid behavior. Prior Adreno generations struggled on this compute workload, which is strange because the program generally performs well across a wide range of AMD, Intel, and Nvidia GPUs. Adreno X1 could not run FluidX3D unmodified, so Cheese worked with Longhorn to get a patched version of FluidX3D working.
The patched version also included performance-related tweaks, namely changing the workgroup size from 64 to 128 and setting the legacy_gpu_fma_patch flag. The latter uses a*b+c instead of OpenCL’s built in fma function. OpenCL’s fma function does not allow rounding intermediate results, reducing error compared to a*b+c.

Even with those flags set, Adreno X1 performs poorly against comparably positioned AMD and Intel iGPUs. Even the HD 530 iGPU in Intel’s Core i5-6600K is nearly 3x faster. Adreno X1 is at least less of a disaster than prior Adreno GPUs, if that’s any consolation.
Since I (Clam) don’t have the Snapdragon X Elite system on hand, I checked the effects of each change on my Zenfone 9’s Adreno 730. Adreno 730 can’t allocate a large enougb buffer to handle the FluidX3D benchmark’s 256x256x256 grid, so runs on Adreno 730 used a 128x128x128 grid.

On Adreno 730, the legacy_gpu_fma_patch flag produced huge gains. Maybe Qualcomm doesn’t have fast hardware for fused multiply-adds without intermediate rounding. Adjusting the workgroup size also increased performance, but had negligible impact when combined with the legacy_gpu_fma_patch flag. On the Intel Core Ultra 7 155H, the legacy_gpu_fma_patch made no difference, and doubling the workgroup size only made it marginally faster.
FluidX3D can be compiled to use FP16 formats for storage, which reduces memory capacity and bandwidth requirements. Unfortunately, Adreno X1 was unable to complete a FluidX3D benchmark run when using those FP16 modes.
Cyberpunk 2077
Cyberpunk 2077 is a DirectX 12 game that can be demanding at high settings. However, it does maintain decent visuals at low settings, making it playable on recent integrated GPUs. Here, we’re testing a few devices from different people in the Chips and Cheese Discord. The goal here is to get an idea of where the Snapdragon X Elite sits. Comparing chips in isolation is not the goal, because performance for any mobile chip varies heavily depending on the platform it’s implemented in. OEMs may choose to set different power power management policies. And unlike desktops, cooling performance is often a major factor.
We ran Cyberpunk 2077’s built in benchmark at the low preset with upscaling disabled, at 1920×1080 and 1280×720. While laptops here have higher resolution screens, targeting those resolutions is impractical using an iGPU in a thin and light laptop.

At 1920×1080, the Snapdragon X Elite achieves a borderline playable 24 FPS average. It’s not the best performance compared to Meteor Lake and Phoenix, both of which manage to break the 30 FPS mark. On the bright side, Qualcomm has managed a dramatic performance improvement over the Adreno 690 used in the Snapdragon 8cx Gen 3.
Qualcomm evaluated a higher end X1E-84-100 chip against the Core Ultra 7 155H. The X1E-84-100 runs the iGPU at 1.5 GHz compared to the X1E-80-100’s 1.25 GHz iGPU clock. If we assume linear clock speed scaling, the X1E-84-100 has a chance of getting within striking range of the Core Ultra 7 155H as implemented in the Asus Zenbook 14.

Of course, performance often does not scale linearly with clock speed. Also, a higher end Meteor Lake part (the 185H) with better cooling can get better performance as well.
Many laptops reduce performance when running off battery power, but Snapdragon X Elite maintains the same level of performance. Meteor Lake in contrast takes a small performance loss, which leaves it with just a 17% performance advantage over the Snapdragon X Elite.

Framerates are still a bit low at 1080P, especially on battery. AMD’s Phoenix still stays above 30 FPS, especially in a purpose built gaming handheld. For Meteor Lake (on battery) and Snapdragon X Elite though, 720P might be a more practical target. 720P might seem like a low resolution in 2024, but we should remember that Valve’s popular Steam Deck ships with a 720P screen. Very often, low resolutions are the best way to enjoy recent PC games in a thin and light device.

At 720P, Snapdragon X Elite comfortably breaks the 30 FPS barrier. It’s still behind Meteor Lake, but both iGPUs should provide comfortably playable performance. Phoenix does very well here with a 60 FPS average. Qualcomm has managed more than a 3x performance improvement over the older 8cx Gen 3. That sort of progress is commendable, and shows Qualcomm is serious about taking on more demanding titles.

Again, switching to battery power makes no difference for the Snapdragon X Elite. AMD’s Ryzen 7840HS also continues to perform very well. However, Meteor Lake sees a substantial framerate drop. I suspect that’s because Asus Zenbook 14 doesn’t like to draw over 40W from the battery. Power draw from the USB-C port was around 45W when running off wall power. Running at 720P increases CPU load, and Meteor Lake seems to handle badly when the CPU and GPU start competing more for a limited power budget.

Normalizing for power draw is a task best left to mainstream sites with more resources and the ability to control testing circumstances. However, we can make basic platform power estimates by examining battery discharge rate. HP was willing to draw more power from the battery.
AMD and Intel also have sensors that can estimate the chip’s power draw, and those package power figures align with what we see above. The Ryzen 7840HS, reported an average package power draw of 31.5W during the 1080P, while the Core Ultra 7 155H reported a lower average of 23.8W. We used HWInfo to gather information, since it’s easy to use a publicly available utility when crowdsourcing test data.
Raytracing?
Qualcomm’s Snapdragon 8 Gen 2 introduced hardware accelerated raytracing, and Adreno X1 inherits that. Unfortunately, Adreno X1 does not support DirectX 12 Ultimate, so most PC games that support raytraced effects won’t be able to use them on Adreno X1. Raytracing is only supported through the Vulkan API, which we can test with 3DMark’s Solar Bay test.

3DMark Solar Bay showcases raytraced reflections on a small scene with otherwise simple effects. Adreno X1 turns in a competent performance, but lands behind AMD’s Phoenix and Intel’s Meteor Lake.

Framerates reported by the benchmark are quite good across all three chips. Intel has the strongest raytracing performance here. But my opinion remains the same as before. Raytracing in practice comes with a heavy performance hit. Mobile iGPUs with ultrabook power budgets don’t have the performance necessary to go after good visuals even without raytracing, and definitely don’t have the headrooom needed to enable raytraced effects. Qualcomm may be a tad behind its competitors here, but it doesn’t matter because raytraced effects are firmly out of reach for all three GPUs.
Drivers and Software
In isolation, Adreno X1 is strong enough provide playable performance in some AAA games. But having GPU power to provide decent performance means little if the game doesn’t run correctly. While Qualcomm gets credit for getting a DirectX 12 game like Cyberpunk 2077 working, not all games are that lucky.

Civilization 5 is one such example. It’s an older game that uses the DirectX 11 API. It suffers rendering artifacts on Adreno X1. Some games don’t even launch, as noted by Digital Foundry. Intel notably had driver struggles when they launched their Arc A770 and A750. Intel had years of experience getting PC games to run on integrated graphics, even if those iGPUs lacked the power to go for high settings resolutions. Qualcomm comes from an even more difficult spot because they don’t have the same experience.
Qualcomm’s driver release process needs work too. Their drivers are available on GitHub, and different devices get different driver packages. The drivers don’t come with automated installers, so users have to extract CAB files and use a manual driver installation process. Even in the Windows 95 days, hardware manufacturers shipped driver installer executables that carried out this process under the hood. We carried out this process to try getting onto the newer June 10th driver, but after the update, Cyberpunk 2077, Civilization 5, Disco Elysium, and Bad Rats all failed to launch. Therefore, all testing here was carried out on the May 17, 2024 driver.
AMD, Intel, and Nvidia offer unified driver packages where a single driver download covers multiple GPU generations across a wide variety of devices. Users can click through an automated installer and have the new driver running in a matter of minutes. That sort of streamlined experience stands in stark contrast to Qualcomm’s bare bones one. That’s worse because an AMD, Intel, or Nvidia GPU user doesn’t have to go through the driver update process too often. Most games will run fine on outdated AMD, Intel, or Nvidia drivers. An Adreno X1 user will likely be frequently checking for updates because Qualcomm’s drivers are in such rough shape right now.
To Qualcomm’s credit, publishing drivers in any form is a huge improvement over the Android ecosystem, where users had to rely on OEMs for driver updates. Hopefully Qualcomm will quickly iterate on providing both better drivers and a more streamlined driver update process. For now, the driver situation will likely make Adreno X1 frustrating to non-technical users.
Final Words
Qualcomm, AMD, and Intel have all approached the laptop iGPU challenge from different directions. AMD has a strong background in making powerful discrete GPUs, and their mobile chips feature scaled down versions of the architecture implemented in discrete cards. Qualcomm came from making cell phone chips, where power and memory bandwidth constraints drove a different set of design choices. Intel has a lot of experience targeting the PC market, but spent much of that time aiming for low performance designs.

Against AMD’s Phoenix and Intel’s Meteor Lake iGPUs, Adreno X1 has competitive compute throughput for basic 32-bit and 16-bit floating point math operations. The Snapdragon X Elite has better DRAM bandwidth than the competition, thanks to a very fast LPDDR5X controller. Qualcomm also deserves credit for flexibly using their GMEM block as local memory, render cache, or a tiled rendering buffer depending on what the situation calls for.

But Adreno X1’s cache bandwidth is low and latency is mediocre. Register file capacity isn’t high enough considering Adreno’s very wide wave sizes. GMEM flexibility is great, but Adreno still feels like a GPU optimized for the DirectX 11 era where pixel shader work dominates. On the compute side, performance with 64-bit integers is poor, and FP64 support is absent. Drivers and supporting software are in rough shape.

I hope Qualcomm dramatically improves Adreno’s situation in the coming months and years. Shoring up the software side would do a lot in the short term. In the longer term, Adreno will have to evolve to keep up with Intel and AMD’s offerings. AMD’s Phoenix and Intel’s Meteor Lake already present strong competition, and both companies will be constantly improving their GPUs to compete for control of the mobile PC gaming market. If Qualcomm pulls that off, we’ll all benefit from more competition in the laptop iGPU space.
Again, we would like to thank our Patreon members and Paypal donators for donating and if you like our articles and journalism then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.