
Intel’s Lion Cove Architecture Preview

Intel’s P-Core’s lineage can be traced all the way back to the P6 architecture that was originally found in the Pentium Pro. From the Pentium Pro to Pentium III to Sandy Bridge to Golden Cove, Intel’s P Cores have had many changes over the years and Lion Cove is no different and in one respect is a major departure from all prior P6 derived cores.
Splitting the Scheduler
Getting straight into the biggest change, Intel has split the Unified Math Scheduler into an integer scheduler and a vector scheduler. Now instead of having one unified penta-ported math scheduler, Lion Cove has a hexa-ported integer scheduler and a quad-ported vector scheduler.

While a split scheduler layout will need more scheduler slots then a single unified scheduler, Lion Cove has about double the amount of scheduler slots compared to the prior generation Golden Cove’s unified scheduler.
But there are benefits to the splitting of the scheduler with the 2 major benefits being better power efficiency of the core and, perhaps surprisingly, simplifying the core. The first benefit, better power efficiency, comes from being able to better clock gate the scheduler section of the core. For example, if there is no vector code being executed then the vector scheduler can be clock gated in order to either reduce the total power consumption of the core or reallocating that power to other parts of the core potentially allowing parts of the core to clock higher.
The second major benefit of splitting the scheduler is simplifying the design. While that may seem odd, if you dig a little deeper, it makes a lot of sense. With a single pentaported scheduler where all 5 ports have to deal with vector instructions that have 3 operands, as well masking, means that you have to have a total of 15 ports as well as masking support. So adding any more ports to this setup would have been incredibly prohibitive.
With the new split setup, only the 4 port vector scheduler will now need to deal with 3 operand instructions and masking meaning you only need to deal with 12 operands along with masking. Now on the Integer side, even though there are now 6 ports compared to the previous 5 ports, the scheduler only needs to deal with 2 operand instructions and no masking. So even with the extra port, the scheduler only has to deal with 12 operands.
Cache Hierarchy Changes
There has been a big change to the cache hierarchy with the addition of a new intermediate cache.

Intel has done some relabeling of the cache hierarchy. What was known as the L1 in prior Cove cores, is now being called the L0. With the changes made, Intel has managed to decrease the latency of the L0 back down to the 4 cycle latency that Skylake had but kept the increased size of later Cove cores.
There is now a new intermediate cache that Intel is calling the L1. The reasoning for this cache is that Intel wanted to have a cache larger then the 48KB of the L0 but low latency is key for the lowest level cache that a CPU has access to. So this new L1 cache is a much larger 192KB but it also is 9 cycles worth of latency. This will act as a buffer between the faster and smaller L0 and the slower but much larger L2. Speaking of the L2, Intel has managed to increase the L2 size up to 3MB. Yet despite adding a new cache level as well as increasing the size of the L2, the latency has only increased by a single cycle to 17 cycles total.
In terms of bandwidth, both the L0 and L1 can do up to 128B per cycle which is the same as the L1 found in prior Cove cores. However, while the L2 can in theory do up to about 110B per cycle Intel has made the engineering choice on Lunar Lake to limit the L1 to L2 bandwidth to 64B per cycle for power and area savings.
Hyperthreading Optional
The rumor mill has been abound with the rumor that Lion Cove will not have Hyperthreading, which is partly true. In Lunar Lake, Lion Cove has not only had Hyperthreading disabled but Intel has gone one step farther and they have removed the parts that enable Hyperthreading from the core found in Lunar Lake.
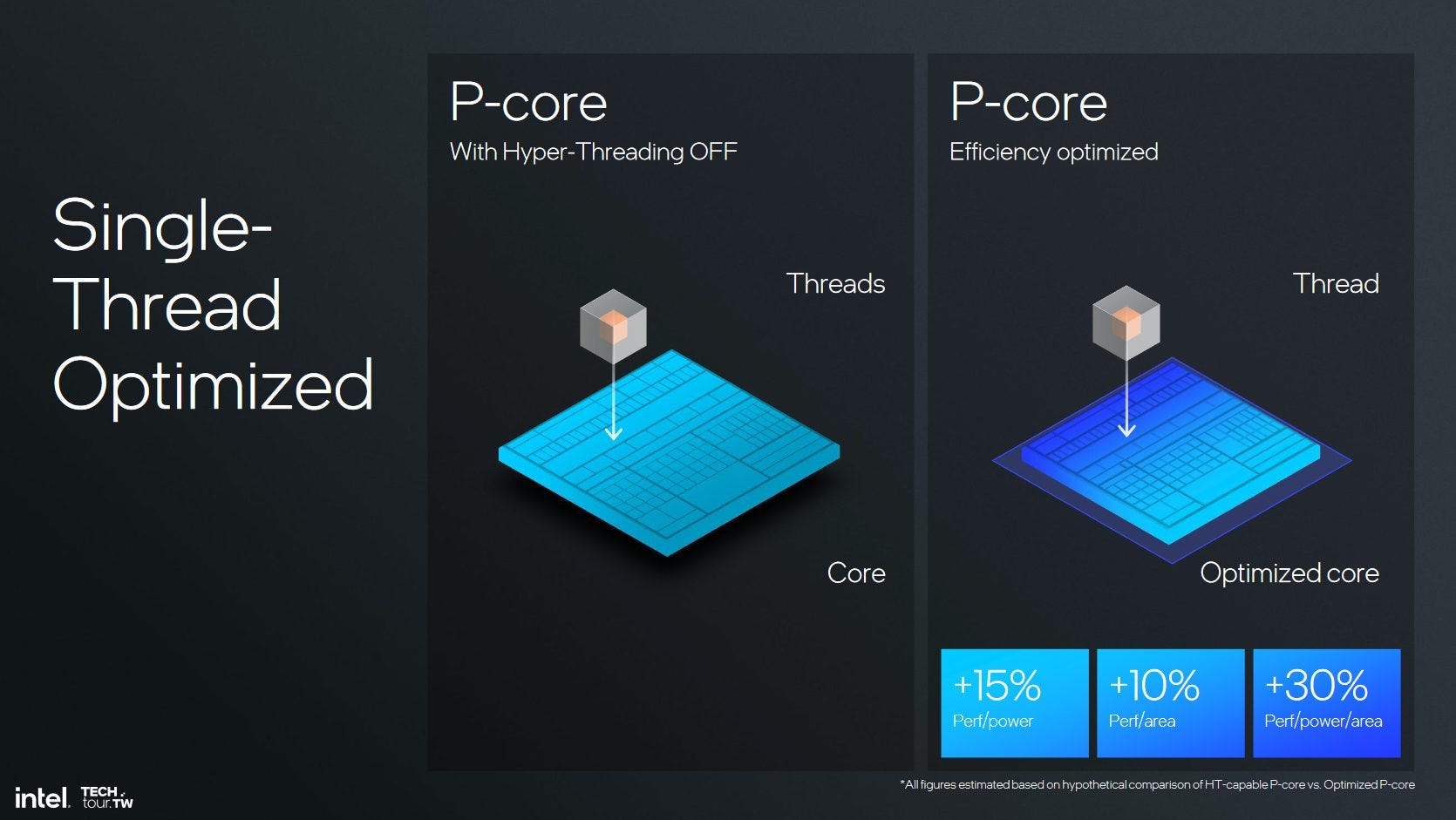
The removal of Hyperthreading makes a lot of sense for Lunar Lake to both reduce the die size of the version of Lion Cove found in Lunar Lake along with simplifying the job of Thread Director.
On Meteor Lake, Thread Director had four places to put a program: P-Core, P-Core Thread, E-Core, and the LP E-Core. This was a lot of complexity that Thread Director had to handle. Lunar Lake does away with a lot of the complexity by only having P-Cores and E-Cores for Thread Director to worry about. However, the removal of Hyperthreading doesn’t make sense for all the products that Lion Cove will be used in.
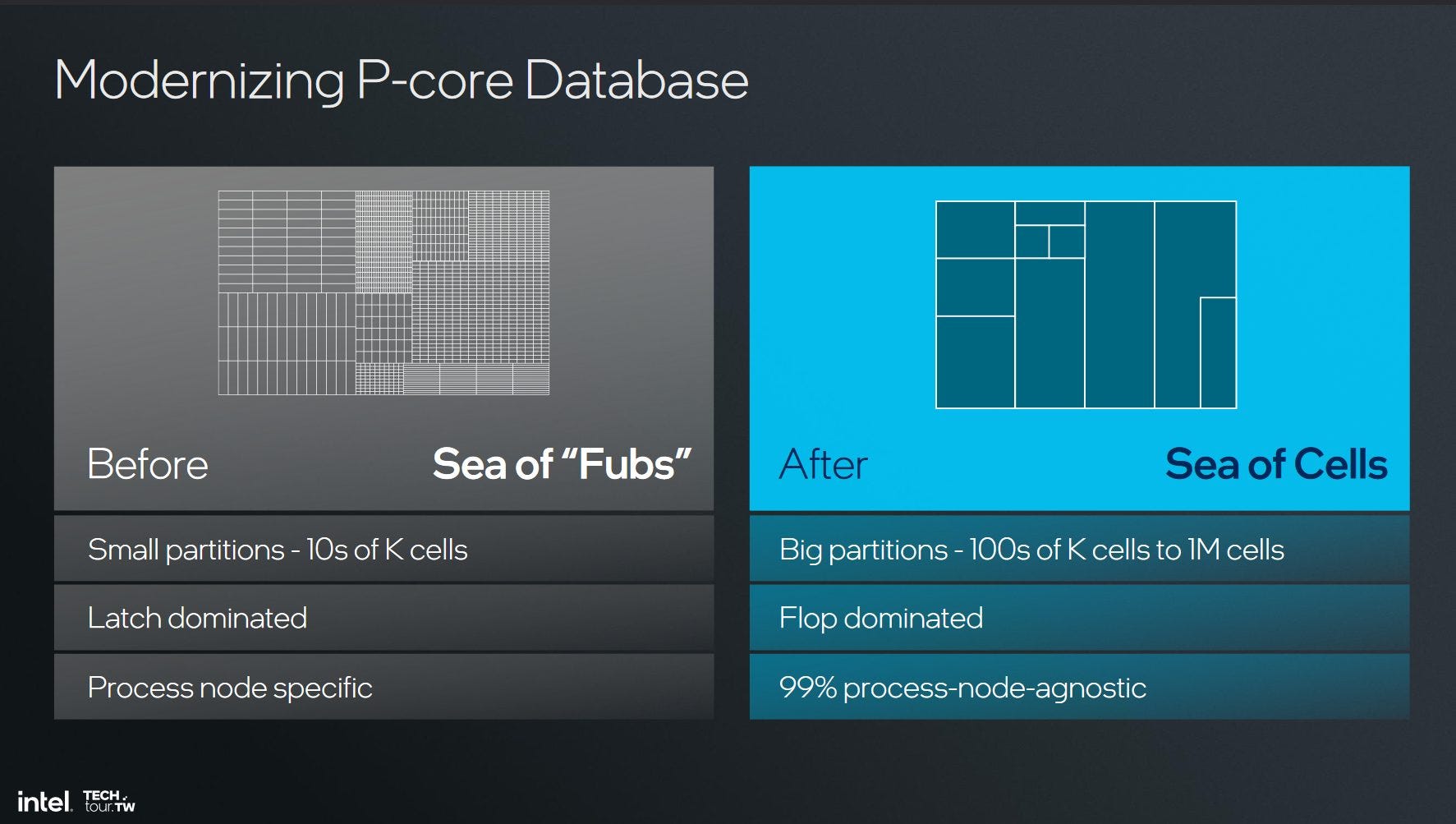
With the move from a Sea of “Fubs” to a Sea of Cells, Intel is now able to better customize a single architecture for multiple products. This means that while Lunar Lake may not support Hyperthreading, other products like Arrow Lake or a hypothetical future server CPU that use future P-Cores could support Hyperthreading if the application can benefit from it.
Other Improvements
Intel has improved other parts of the Lion Cove core such as the front-end and the total number of resources in the out of order engine.

Intel has increased the fetch to 48 Bytes per cycle with Lion Cove, increased the size of the Uop cache, and improved the branch prediction. These improvements in Lion Cove serve to feed the widened back-end.

Lion Cove has widened the core from 6 wide found in Redwood Cove to 8 wide as well as increased the reorder buffer from 512 to 576 entries. Now, Intel hasn’t stated if the register files have been increased in size but Ori Lempel, Senior Principal Engineer, said “Structures associated with the reorder buffer have been increased accordingly.”

On the integer execution side, Intel has increased the number of ALUs to 6 with Lion Cove. Also interestingly, Intel has increased the number of integer multiply units from 1 to 3 which is the first time a P-core can do more than 1 integer multiply per cycle. The reason for this is because there are some workloads that really need that added integer multiply capability.

On the vector side, again Intel has added another SIMD ALU taking the number up from 3 to 4. And like the added multiply units found in on the integer side, Intel has added a second floating point divider to Lion Cove as well as improving the throughput and latency of division operations.

Lastly looking at the memory subsystem, Lion Cove has increased the L1 DTLB capacity to 128 entries as well as adding a 3rd store addressing capable AGU.
Conclusions
With the above changes, Intel with Lion Cove has improved the performance per clock by 14% which is quite a nice bump in performance.
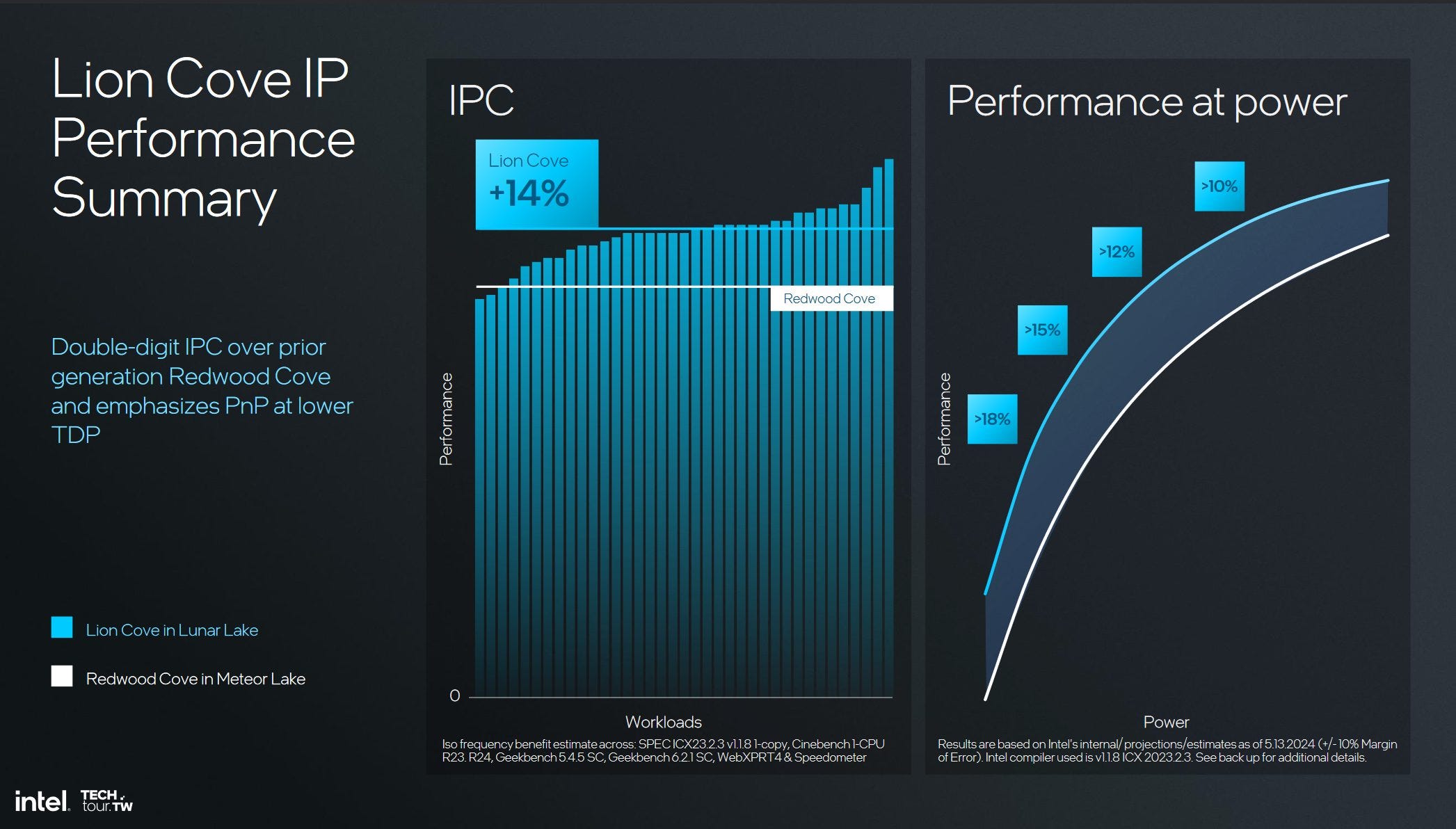
But the headline here is not the performance improvement. It is the shift in thinking that Lion Cove has brought with it. Moving to a more customizable design will allow Intel to better optimize their P-cores for specific designs moving forward.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.