
Thoughts on Skymont Slides

Recently a set of Skymont slides were published, apparently without any embargo or confidentiality marks. I have no proof that the slides are genuine. However, I think they’re worth analyzing because there’s a lot of detail visible. Faking a large set of slides with many points would be very difficult. It’s hard to come up with a lot of fake information and keep it all consistent.

IPC Gains
According to the second slide, Skymont sees a 38% to 68% IPC gain. The latter likely applies to floating point and vector execution. Crestmont and prior Atoms had relatively weak floating point and vector execution capabilities compared to Intel’s P-Cores, so the 68% gain is likely not that hard to achieve.
But if the 38% gain figure applies to a wider range of workloads, it could indicate another turning point in Intel’s Atom strategy. We’ve gotten used to performance per clock gains in the 10-20% region over the past decade, as both Intel and AMD seek to maximize performance through both performance per clock and clock speed gains within area and power constraints. There are exceptions of course. Tremont posted an over 30% IPC gain over Goldmont Plus, as Intel dramatically scaled up the core to make it more suitable as an E-Core companion to higher performance cores.

Tremont dramatically increased structure sizes over Goldmont Plus. Reorder buffer capacity more than doubled, with other resources getting substantial size increases too. A newer process node helped keep power and area consumption in check. We don’t know what node Skymont will be implemented on. If it offers similar gains to moving from Intel’s 14 nm node to their 10 nm one, then Skymont may repeat Tremont’s incredible performance gains at little power or area cost.
But process node improvements have been slowing down, and Intel has struggled to keep pace with TSMC. If Skymont doesn’t benefit from a substantially improved process node, I expect the IPC improvements to either be accompanied by increased area and power consumption, or a decrease in clock speed.
Implementation Goals
Intel’s slides suggest Skymont will be implemented on both desktop and mobile, serving as a follow-on to Gracemont and Crestmont. Interestingly, the slide appears to mention a desktop compute tile. Meteor Lake already uses a compute tile, but so far has been a mobile focused product. Perhaps Intel intends to use the same chiplet strategy on future desktop offerings.
I think a chiplet setup makes more sense in desktop CPUs, where better cooling allows higher core count SKUs to stretch their legs in multithreaded workloads. Hopefully Intel’s chiplet strategy gives them similar flexibility to AMD’s, lowering costs while providing much improved multithreaded performance. Meteor Lake’s ability to provide long battery life also gives me hope that Intel’s desktop chiplet offerings will also benefit from low idle power. That’s been a weak point for AMD’s chiplet offerings on desktop, which can suffer from high idle power unless you disable XMP.
Frontend Changes
Crestmont’s frontend used two 3-wide fetch and decode clusters, with the branch predictor load balancing between the two as in Gracemont and Tremont. Skymont adds another cluster, making the frontend 9-wide. In that respect it’s similar to Zen 4, which can deliver 9 macro-ops per cycle from its op cache. The sixth side also has a point about uop queue capacity. Presumably, those queues are bigger to let the frontend run further ahead of the backend.

Skymont’s branch predictor needs to move quickly through the instruction stream to stay ahead of fetch/decode and keep those stages fed. Crestmont laid the groundwork for this, increasing prediction width to 128 bytes per cycle. Skymont benefits from this, but Intel has also made the branch predictor faster in unspecified ways.

Feeding this very wide frontend will come with challenges. Skymont’s instruction cache will have to service up to three accesses per cycle and deliver up to 96 bytes per cycle. Furthermore, the increased frontend bandwidth will have little impact if the out-of-order execution engine can’t keep up, or if instruction cache misses starve the decoders.
Out-of-Order Execution
After the frontend brings instructions into the core, Skymont can do register renaming and backend resource allocation for up to 8 instructions per cycle. Thus the core is overall 8-wide. It can sustain eight instructions per cycle. The 8th slide mentions dependency breaking, but doesn’t give specifics. Crestmont and prior Atoms could all break dependencies via move elimination or recognizing operations that always result in zero.
Skymont then has deeper queues and more out-of-order resources, letting it keep more instructions in flight to hide cache and memory latency. Doing so is vital to taking advantage of the wider frontend and renamer. Squinting at the slide suggests it says Skymont has a larger out-of-order scheduler and bigger physical register files. I can’t figure out what the last two lines say. But reordering capacity is limited by whatever resource runs out first, so it’s reasonable to assume Intel increased other structure sizes to keep things in balance.
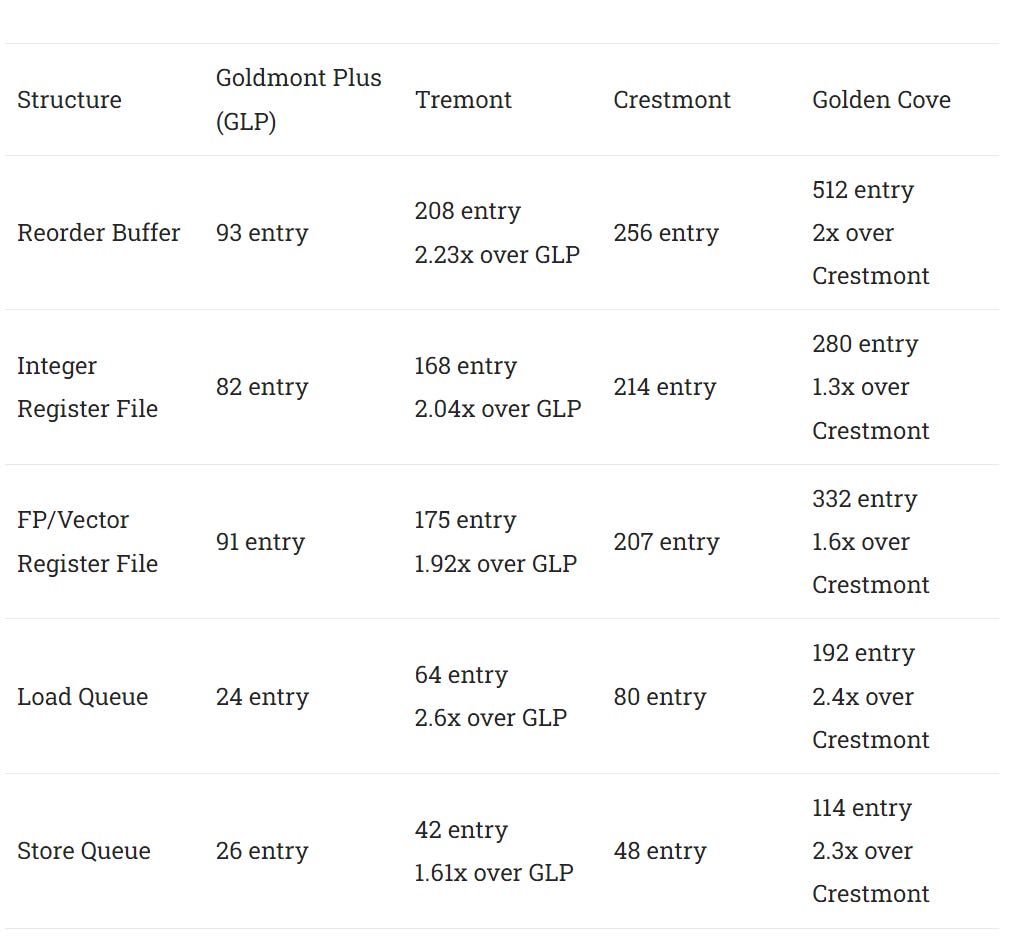
Tremont massively increased structure sizes compared to Goldmont Plus. Those increases likely played a large role in its huge 30+% IPC gains. If Skymont gets similar increases, its structure sizes would be very close to Golden Cove’s.
The 8th slide has another “16-wide” point. I don’t know what that refers to, but one guess is execution port count. Gracemont and Crestmont already had 17 execution ports. Perhaps Skymont has similar execution width, with one less-used port cut to control power and area. Or, Intel could simply be counting execution ports differently.
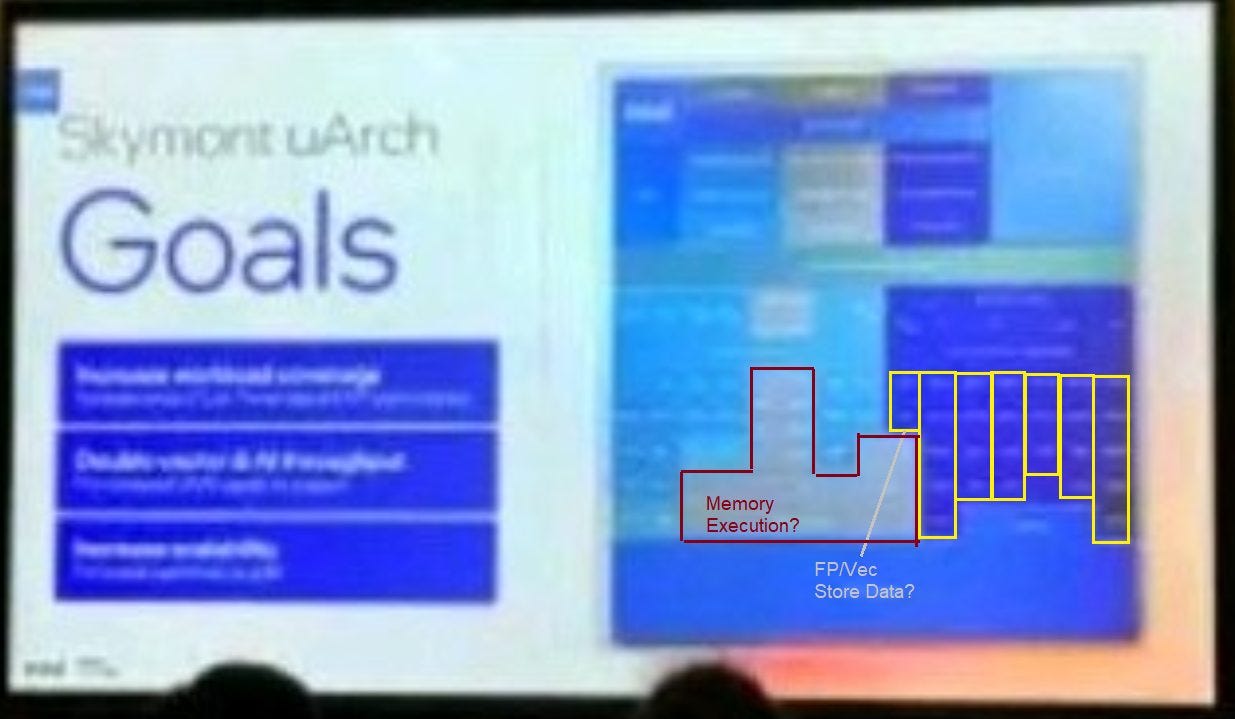
The 5th slide shows Skymont’s rough execution layout, though there are too few pixels to establish anything concrete. If the dark blue area is the FP/vector side though, Skymont might have twice as many FP/vector math execution ports compared to Crestmont. The slide text certainly seems to say either “Double vector & FP Throughput” or “Double vector & AI Throughput”. Both would be consistent with doubling execution pipe count, since AI benefits from vector execution too. That could contribute to Skymont’s large FP performance gain, if that’s what the 68% figure points to.
Final Words
Intel’s Atom line has grown to be an important component of the company’s CPU strategy, with E-Cores taking an increasingly prominent role. Skymont appears to be another step in the same direction. Massive performance per clock increases would bring Skymont closer to achieving P-Core performance, particularly if power and thermal constraints prevent P-Cores from reaching their very high boost clocks.
If Skymont is improving performance by going for large IPC gains instead of clock speed increases, it does mirror Apple and Arm’s strategy. Apple and Arm have kept clock speeds relatively low while implementing ever larger out-of-order execution engines. That strategy has served them well in very power constrained devices like fanless tablets and cell phones. I’m looking forward to seeing how Skymont stacks up.