
Qualcomm’s Oryon LLVM Patches

In October of 2023, Qualcomm announced its newest Laptop SOC lineup called the Snapdragon X Elite (SDXE). There has been a ton of excitement around this chip since then, due to it using a custom ARM core from the Nuvia team that Qualcomm acquired in early 2021.
That makes this chip a fairly unique offering in the ARM SOC realm (outside of Apple) because most companies choose to purchase off-the-shelf core IP from ARM themselves. With the expectation of a launch of SDXE laptops at Computex, there is a lot of excitement over the chip, but there has been very little information about the core itself.
Luckily there was an LLVM patch uploaded not to long ago that discusses some of the structure layout of the Oryon core found in the Snapdragon X Elite, so let’s dive in.
Pipeline Description
Starting with the Branch Mispredict penalty, the Oryon core has a mispredict penalty of 13 cycles. Zen 4’s average penalty is also 13 cycles however that is dependent on just how often Zen 4 is feeding out of the Op Cache.
The branch misprediction penalty is in the range from 11 to 18 cycles, depending on the type of mispredicted branch and whether or not the instructions are being fed from the Op Cache. The common case penalty is 13 cycles.
Software Optimization Guide for the AMD Zen4 Microarchitecture
Moving on to the L1 Data Cache, sadly the size of the L1D is not said in this patch but it does say that the load-to-use latency for the L1D is 4 cycles. This is fairly standard for a modern core clocking around 4.2GHz and puts the absolute latency of the L1D at a hair under one nanosecond. This absolute latency is comparable to Apple’s Firestorm core but Firestorm had a 3 cycle L1D at about 3.2GHz.
Issuing Width, Pipes, and Schedulers
Oryon can issue up to 14 operations per cycle with 6 pipes for the integer side, 4 pipes for the vector side, and 4 pipes for the memory side.
The Integer Side
Beginning with the integer side, there are a total of 6 pipes and 6 ALUs.

Compared to other high performance cores, Oryon’s integer throughput is most similar to Firestorm. One difference is the compare throughput at 4 per cycle on Oryon, versus 3 per cycle on Firestorm.

Oryon’s 120 entry integer scheduler is fairly large compared to its x86 counterparts. Zen 4 has a total of 96 entries in its integer scheduler, however those 96 entries also have to deal with all memory operations. Golden Cove has 97 entries in it’s unified math scheduler but, as the name implies, that scheduler has to deal with both integer and vector operations.
Comparing to other ARM cores Oryon is on the larger end of the spectrum with Cortex X2 having 96 entries for its integer scheduler but with Neoverse V1 having 124 entries in its integer scheduler. However Apple’s Firestorm and M3 P-Core have a total of 156 and 160 entries in their respective integer schedulers which are ~30-33% larger then Oryon’s scheduler.
The Vector Side
Turning our gaze to the Vector side of the core and the similarities to Firestorm and M3 P-Core get even stronger.

The vector instruction throughput and latencies of both Oryon and Firestorm are nearly identical; the one difference is that Oryon has 2 cycle latency for SIMD INT MUL versus 3 cycles for Firestorm.
Another thing that Oryon, Firestorm, and M3 P-Core all share is a lack of SVE or SVE2. Which means that the only SIMD operations that these 3 cores can execute are NEON operations. NEON is a much more limited set of operations compared to the AVX512 operations that Zen 4 or Server Golden Cove support.
Now moving towards the scheduler layout, and Oryon again has similarities to Firestorm and M3 P-Core.

Oryon’s vector scheduler is a very large at 192 combined entries, even compared to it’s x86 counterparts. Zen 4’s vector scheduler and the non-scheduling queue combined is only 128 entries. Moving to the ARM side of the field and the Cortex X2 has a mere 75 entries for it’s combined vector scheduler and non-scheduling queue.
Moving to Apple’s side of the field and the situation here is reversed from the integer side: Oryon has larger vector schedulers with 48 entries per scheduler. Firestorm and M3 P-Core also have 4 equal sized vector schedulers but Firestorm only has 36 entries per scheduler and M3 P-Core has 41 entries per scheduler.
The Memory Side
Shifting to the last major section of the CPU and we are going to start with the scheduler layout first.
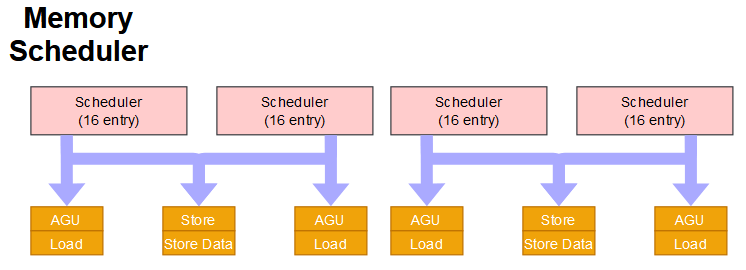
The LLVM patch says that the memory scheduler has 4 ports and that the store pipes share ports with the load pipes.
LSU has 4 ports p6 ~ p9(ls0 ~ ls3), p10/p11(std0, std1) has to work with ls0~ls3
This suggests that Oryon has 4 pipes, all of which can handle load operations but only 2 of which can deal with store operations at any one time. This is reinforced later on in the LLVM patch which implies that store instructions can fill all 64 entries in the memory scheduler.
Store instructions on combo of STA/STD pipes
def ORYONST : ProcResGroup<[ORYONST0, ORYONST1]> {
let BufferSize = 64;
Qualcomm Oryon Scheduler LLVM Patch Line 167-169

Now moving to the memory throughput and latency, Oryon can do a total of 4 loads per cycle, regardless of whether they are scalar or vector loads. This is more than any other CPU in this lineup. And in comparison to the other ARM cores, Oryon can handle 33% more load bandwidth. Compared to x86, Oryon has the same load bandwidth as Zen 4 but only 2/3rd the load bandwidth of Golden Cove.
Transitioning to the store side, Oryon has the same store bandwidth as the other ARM cores as well as Zen 4 but again only half of the store bandwidth of Golden Cove. In terms of total bandwidth, Oryon may have the same bandwidth as the rest of the ARM cores but only 66% of the total bandwidth of Zen 4 and Golden Cove.
Final Words
According to this LLVM patch, there are many similarities to Firestorm. This isn’t a great surprise considering that a lot of the Nuvia team worked on Firestorm. But this is not to say that Oryon is a copy of Firestorm, the LLVM patch highlights some critical differences between the two cores. We are looking forward to seeing Oryon when laptops using the Snapdragon X Elite hit the shelves, because outside of Apple and now Qualcomm, only Huawei is trying to make high performance custom ARM cores for client devices currently.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.
References
Qualcomm Oryon LLVM patch: https://github.com/llvm/llvm-project/blob/8aebe46d7fdd15f02a9716718f53b03056ef0d19/llvm/lib/Target/AArch64/AArch64SchedOryon.td
Cortex X4 Instruction Throughput and Latencies: https://developer.arm.com/documentation/PJDOC1505342170538636/r0p1/?lang=en
Apple Instruction Throughput and Latencies: https://developer.apple.com/documentation/apple-silicon/cpu-optimization-guide
Firestorm Scheduler Sizes: https://dougallj.github.io/applecpu/firestorm.html
M3 P-Core Scheduler Sizes: https://www.youtube.com/watch?v=iSCTlB1dhO0&pp=ygUNZ2Vla2Vyd2FuIGExNw%3D%3D
Golden Cove and Zen 4 Instruction Throughput and Latencies: https://uops.info/table.html