
Loongson 3A6000: A Star among Chinese CPUs


Computing power has emerged as a vital resource for economies around the world. China is no exception, and the country has invested heavily into domestic CPU capabilities. Loongson is at the forefront of that effort. We previously covered the company’s 3A5000 CPU, a quad core processor that delivered reasonable performance per clock, but clocked too low to be competitive.
Now, we’re going to look at Loongson’s newer 3A6000 CPU. The 3A6000 is also a quad core 2.5 GHz part, but uses the newer LA664 core. Compared to the 3A5000’s LA464 cores, LA664 is a major and ambitious evolution. While Loongson has kept the same general architecture, LA664 has a larger and deeper pipeline with more execution units. To sweeten the pie, LA664 gets SMT support. When properly implemented, SMT can increase multithreaded performance with minimal die area overhead. But SMT can be challenging to get right.
Sizing Up 3A6000
7-Zip is a file compression program that achieves high compression efficiency, but can demand a lot of CPU power. It almost exclusively uses scalar integer instructions, so SIMD extensions don’t play a role. Here, we’re compressing a large ETL performance trace.
The 3A6000 provides a massive 38% performance gain over its immediate predecessor, and that gain increases if we take SMT into account. With one thread loaded per core, four LA664 cores are roughly equivalent to four Zen 1 cores in this workload. LA664’s performance per clock is therefore very good because it’s only running at 2.5 GHz, but those low clocks prevent it from catching AMD’s newer parts.

With all threads loaded, SMT gives the 3A6000 a 20% performance improvement. Meanwhile, AMD enjoys 40%+ SMT gains on Zen 1 and Zen 2. SMT serves to give a core more explicit parallelism, helping it hide latency and keep its pipeline better fed. On one hand, a high SMT gain indicates the core’s SMT implementation is well tuned. On the other, it means the core isn’t doing a good job of hiding latency when running a single thread.
Unlike 7-Zip, libx264 video encoding makes heavy use of SIMD instructions. On x86 CPUs, the encoder will use SSE, AVX, AVX2, and even AVX-512 if available. On Loongson, libx264 will leverage the LSX and LASX SIMD extensions. Here, I’m transcoding a 4K Overwatch gameplay clip.

The 3A6000 brackets Zen 1, taking either a slight win or loss depending on whether we use all SMT threads or restrict the task to one thread per core. Zen 1’s typically high SMT gains may be limited by its weak AVX2 implementation. Zen 2 and the 3A6000 both see 30%+ SMT gains. With an all-around improved architecture and a solid AVX-512 implementation, AMD’s latest Zen 4 architecture pulls away from the rest. As before, the 3A6000 performs admirably well for a 2.5 GHz CPU.
Core for core, LA664 brings Loongson out of the low performance bracket and into competition with older AMD and Intel high performance parts. Zen 1 is roughly comparable to Haswell, and both architectures remain serviceable even today. Now, let’s look at the core architecture that lets Loongson compete against those higher clocked designs.
Core Architecture
The LA664 is a 6-wide out-of-order core with substantial execution resources and deep reordering capacity. It’s competitive with recent Intel and AMD cores in those terms.
LA664 builds on LA464’s foundation. The LA464 core in Loongson’s 3A5000 is a four-wide out-of-order design, but is more modestly sized in all respects. LA464 was a solid core overall with few glaring weaknesses, and provided a strong foundation for Loongson’s efforts. It’s no surprise that LA664 inherits a LA464’s general architecture.

Of course, a block diagram doesn’t tell the whole story. Factors like branch prediction, execution latency, and memory access performance can have a huge impact.
The Loongson 3A6000’s Frontend
Branch Prediction
A CPU branch predictor is responsible for directing the frontend. It is what tells the CPU what direction a branch will go and this is very important because if the branch predictor gets the direction wrong, the back end of the CPU will end up wasting a lot of performance, power, and time on work that doesn’t matter.
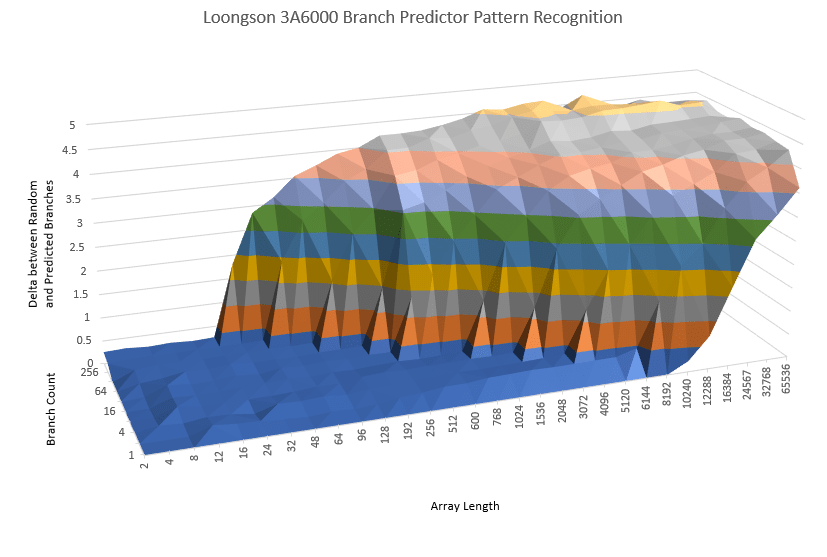
The 3A6000’s branch predictor has impressive pattern recognition capabilities, and is easily the best among Chinese CPUs we’ve seen so far. It’s worlds apart from what we saw in the 3A5000, and comes within spitting distance of recent Intel and AMD CPUs. However, AMD has been investing heavily in branch predictor capabilities. Their Zen 3 architecture is still a step ahead.

Zen 3 accomplishes this by using an overriding predictor. Most branches have simple behavior and can be handled quickly by the first level. The more capable but slower second level only has to step in for branches that have long history. With this scheme, Zen 3’s branch predictor is able to track very long branches while maintaining high speed.
Even if the 3A6000 isn’t a match for AMD’s recent cores, Loongson has made commendable progress. The 3A5000 predictor looks more fit for a high performance core from the mid ’00s to the early ’10s than something from this decade. Loongson’s investments in this area are no doubt a large factor behind 3A6000’s improved performance.
Branch Predictor Speed
A branch predictor has to be both fast and accurate to avoid starving the core of instructions. Branch target buffers cache branch targets, letting the predictor follow the instruction stream without waiting for the actual branch instruction bytes to show up. The LA664 has a 64 entry L1 BTB capable of handling taken branches back to back, or “zero bubble” in AMD’s presentation language. BTB misses are likely handled by simply waiting for the instruction bytes to arrive from the 64 KB instruction cache, and then using the branch address calculator to compute the destination. This effectively looks like a 1K-4K entry L2 BTB tied to the instruction cache.

In contrast, AMD and Intel’s recent architectures use a large L2 or even L3 BTBs decoupled from the instruction cache. Grabbing an address from another BTB level can be faster than waiting for instruction bytes to arrive, and AMD’s Zen 4 takes advantage of that to allow very low latency branch handling as long as BTBs can contain the branch footprint.

Furthermore, decoupling the BTB from the instruction cache helps maintain high IPC as code spills out of L1i, because the predictor is insulated from L1i miss latency. But Loongson’s decision to forgo a big, decoupled BTB isn’t unique. Tachyum Prodigy similarly decided such an approach would be too expensive, because they would have trouble hitting their clock speed targets with standard cell libraries. Like Tachyum’s Prodigy, 3A6000 compensates for this by using a large 64 KB instruction cache. If the predictor has to cope with less L1i miss latency, then its weaknesses there won’t matter as much.
The 3A6000 also appears to have more aggressive linear instruction prefetching. The test above simply has branches jumping to the next 16B aligned block, so a linear instruction prefetcher can cope quite well. AMD in contrast appears to have prefetching driven entirely by the branch predictor. Once we exceed BTB capacity, we’re basically looking at L2 latency.
Indirect Branch Prediction
Indirect branches are trickier then direct branches to predict. Instead of directly encoding the target that the branch needs to jump to, an indirect branch jumps to an address in a register. The 3A6000 does very well with indirect branch prediction.

3A6000 can track 1024 total indirect targets which is a doubling of what the 3A5000 can do. 3A5000 could only track around 24 single indirect branches where as 3A6000 can track well over 128 single indirect branches. For a comparison, Zen 2 can also track 1024 indirect targets so 3A6000 is very much in line with fairly recent x86 CPUs.
Return Prediction
Return operations stand out as a particular kind of indirect branch, often observed in harmonized call-and-return duos. It’s common for numerous computer processors to employ a stack reserved for the addresses to be returned to. When the branch predictor sees a call instruction, it pushes an address into this stack. When it sees a return instruction, it pops an address off the stack. Oddly enough, 3A6000 ended up reducing the return stack from the 32 entries in 3A5000 to only 16 entries. Effective capacity can drop even further to 8 entries if both of the core’s SMT threads are active.

Dropping return stack capacity to 16 entries is somewhat justified, as even a smaller return stack can capture the majority of call/return cases. Loongson may be falling back to the indirect branch predictor as the 3A6000 only suffers a modest performance drop once the return stack overflows. Intel uses the same strategy. In that case, the return stack can be seen as a power and performance optimization rather than being critical to performance.
Branch Prediction Accuracy
7-Zip and other compression workloads often present formidable challenges for CPU branch predictors. The 3A6000’s branch predictor copes admirably, and pulls even with Zen 1 in terms of mispredicts per instruction.

In accuracy terms, the 3A6000 draws even with Zen 2. Accuracy is a better metric in this case because 3A6000 was able to compete the workload with fewer executed instructions. Mispredicts per instructions is higher because a larger percentage of Loongson’s instruction stream consists of branches. AMD’s newest Zen 4 architecture is still a step ahead, but Loongson has made commendable progress with their branch predictor. It’s miles better than the 3A5000.
libx264 has fewer branches and more predictable branches, but we can still see differences between tested CPUs. In this test, ISA differences work against Loongson. The 3A6000 sees few mispredicts per instruction, but only because it executes more instructions to complete the workload. Mispredicts matter less when there are more non-branch instructions to deal with.

The 3A6000 branch predictor turns in a comparable performance to AMD’s Zen 2. Loongson again is showing they can play with the big boys when it comes to designing an accurate predictor.
Instruction Fetch
Once the branch predictor has decided what direction the code is going in, it then falls to the instruction cache hierarchy to keep the core feed with data. Much like it’s older brother, the 3A6000 has a a large 64KB 4-way L1i which is a nice chonky L1i compared to comparable Intel and AMD CPUs with only a 32KB L1i. The 64 KB L1i feeds a 6-wide decoder, giving the 3A6000 a 50% wider frontend than its predecessor.

AMD and Intel’s high performance CPUs use a micro-op cache, which can let them avoid instruction decode costs while providing higher throughput. Since Zen, AMD’s micro-op cache can theoretically deliver a full line of 8 micro-ops every cycle, but the core’s throughput is limited by the rename stage downstream.

The Loongson 3A6000 retains good throughput as code spills out of L1i. The 3A5000 inexplicably suffered poor instruction bandwidth when running code from L2. Loongson has since solved that in the 3A6000, which can comfortably sustain 3 IPC when code fits in L2.
Unfortunately the picture isn’t as rosy in the L3 regions. It appears as if Loongson hasn’t improved their instruction fetch from L3 on the 3A6000. And that is a shame because both Golden Cove and Zen 3 can pull over three 4 byte instructions per cycle where as the Loongson CPUs can’t hit two 4 byte instructions per cycle.
Rename and Allocate
Once instructions are decoded into micro-ops, the core has to allocate backend tracking resources. These resources track instruction state and let the core execute instructions as soon as their inputs are ready, while still ensuring correct program behavior and exception handling. This stage also breaks false dependencies via register renaming, and is a convenient place to implement other tricks that expose additional parallelism to the execution engine.
LA664’s renamer has a special case for register zeroing, much like how x86 CPUs recognize xor-ing a register with itself will always result in zero. It completely eliminates such operations, meaning they don’t consume execution resources downstream.

Loongson has also worked some optimizations for register-to-register moves into the renamer. Dependent move r,r instructions can execute at two per cycle, so LA664 can sometimes do pointer manipulation in the register alias tables to break such dependencies. However, it can’t do so at full rate, and register to register moves still require an ALU pipe.
Intel and AMD have both developed far more advanced renamers, capable of eliminating register to register moves at full rate, regardless of dependencies. Intel’s Golden Cove can also eliminate adds with small immediates at the rename stage, further reducing load on the execution pipes.
Out of Order Execution
To enable out of order execution, the rename and allocate stage has to find slots in the necessary queues and buffers to track instruction state. Larger structures let the core look further ahead in the instruction stream, making it better at hiding latency and finding instruction level parallelism. Loongson 3A6000 has a very well sized out-of-order engine and is a massive step up from the 3A5000.

Compared to the 3A5000, primary structures like the register files and memory ordering queues see at least a 25% size increase. LA464 had a disproportionately small branch order buffer, which LA664 fixes. LA664 ends up with comparable reordering capacity to AMD’s Zen 3. Zen 3 and LA664 are still small in comparison to Intel’s Golden Cove, with its giant 512 entry ROB and other larger structures.

SMT Implementation
Bigger out-of-order buffers are vital to increasing single threaded performance, but run into diminishing returns. SMT counters those diminishing returns by exposing multiple logical threads to the operating system, and partitioning resources between the threads. Thus a SMT enabled CPU can maintain maximum single-threaded performance, while working like several smaller cores if more than one of its hardware threads comes out of idle. AMD, Intel, and Loongson have all settled on exposing two SMT threads per core.
While SMT benefits are clear, execution is difficult. The core has to reconfigure itself on the fly when the OS schedules work on more than one of its hardware threads. Engineers have to decide how various core structures will be managed in 2T mode. Namely, a structure can be:
Duplicated. Each thread gets a copy of the resource. In 1T mode, the second copy is simply unused. It’s not an efficient use of die area, but is probably a lot simpler to tune and validate. There are no concerns about one thread getting starved, and there’s no need to drain entries if a second thread becomes active.
Statically partitioned. Each thread gets half of the resource. One thread can use all entries when the other is in halt, so this approach is a more efficient use of die area. It’s harder to validate because the structure will have to be drained and reconfigured when both threads get work. But tuning is still not too hard because cutting the structure in half ensures some degree of fairness between threads.
Watermarked. In 2T mode, one thread can consume resource entries up to a high water mark. There’s more flexibility and more potential performance, but tuning is harder. A higher water mark could improve performance for one thread but have a disproportionate impact on the other (starving it of a critical resource).
Competitively Shared. It’s a free for all. One thread can use all entries even when the other is active. Flexibility and potential performance are maximized. For example if one thread is running FP code and the other is running pure integer code, competitively sharing the schedulers would give let both threads fill the resource they need most. But tuning and validation becomes harder. Starvation is an even more pressing possibility, and engineers have to take care to avoid that.
Loongson has chosen a conservative SMT implementation where most resources are statically partitioned. That applies to the ROB, register files and load/store queues.

Schedulers on the 3A6000 are watermarked. The high water mark seems to be around 30 entries for the math schedulers, so a thread running on 3A6000 can use almost as many scheduler entries as one running on 3A5000 even when its SMT sibling is active.

AMD’s Zen 2 statically partitions the reorder buffer and uses some kind of watermarking scheme for the FP scheduler and non-scheduling queue. But otherwise, AMD has opted for a very aggressive SMT implementation. The register files, load queue, and integer schedulers are competitively shared. That could partially explain Zen 2’s impressive SMT uplifts.
For Loongson, taking a less aggressive and easier to validate approach is probably justified. The 3A6000 is their first SMT enabled CPU, and being too ambitious is a good way to fail.
Integer Execution
3A6000’s integer execution cluster sees the fewest changes from its predecessor, but the 50% increase in scheduler capacity should result in better ALU port utilization. Like 3A5000, 3A6000 has four ALU pipes capable of executing the most common operations. Two ports can handle branches, and two are available for integer multiplies. The setup is roughly comparable to Zen 2’s, but Loongson has two integer multiply pipes compared to Zen 2’s one. Zen 2 has more total scheduling capacity, but comparing its distributed scheduler to Loongson’s unified one isn’t straightforward. Zen 2 could see one of its 16 entry queues fill before the rest, and that would cause a resource stall at the renamer.

Loongson has improved the integer division throughput and latency from 0.11 instruction per cycle and a 9 cycle latency on the 3A5000 to 0.25 instruction per cycle and a 4 cycle latency. This improvement is an odd choice because most code avoids using DIV instructions because they are traditionally very slow. Maybe because Loongson is having to build their software ecosystem from scratch that speeding up division operations would be a worthwhile expense of transistors.
Vector and Floating Point Execution
Loongson’s 3A5000 had 256-bit vector capability with the LASX extension, but had a conservative implementation with two 256-bit pipes. 3A6000 overhauls the FPU. It now has four pipes. All four pipes can handle 256-bit packed FP adds, giving 3A6000 very strong floating point performance. Competing x86 CPUs can only do two 256-bit packed FP adds per cycle. 256-bit packed FP multiplication and basic integer ops see similar performance to Zen 2.
Strangely, scalar FP operations don’t get the same love. Only two pipes can handle scalar FP adds. Even more strangely, scalar FP multiplies appear to use different pipes than vector ones.

Even though Loongson added extra FP pipes, peak fused multiply-add (FMA) throughput remains unchanged. LA464 and LA664 both can execute a single FMA operation per cycle, giving them half the FMA throughput of AMD’s Zen 2 or Intel’s Skylake.

Besides throughput, Loongson has been able to improve execution latencies. FP adds have a latency of 3 cycles, matching Zen 3. However, AMD’s Zen 3 and Intel’s Golden Cove still enjoy lower FP execution latencies. Intel in particular can do FP adds with 2 cycle latency, and do so at much higher clock frequencies as well.
As with the integer cluster, scheduler capacity sees a 50% increase to 48 entries. That by itself probably provides more of a FP performance boost than the extra execution pipes, but both together make the 3A6000 a formidable player in vector and floating point workloads.
AMD’s Zen 2 also has a quad pipe FPU, and can also bring all four pipes to bear for basic vector integer operations. However, it uses a clever non-scheduling queue that lets it avoid renamer stalls even when its 36 entry scheduler fills. That lets the backend hold a lot more in-flight FP or vector operations, even though it can’t search through all of them to find extra instruction level parallelism.
Address Generation
Loongson seriously buffed up the address generation on the LA664 compared to the LA464. LA464 had two general purpose load/store pipes. LA664 splits that into two load and two store pipes.

This means that the LA664 can handle more scalar memory operations per cycle then Zen 3 can and the same amount of memory operations as Golden Cove can. Now Zen 3 and Golden Cove are a bit more flexible in that they can issue up to 3 loads in a cycle compared to LA664’s 2 loads per cycle but this is a significant upgrade from LA464’s single load per cycle. As for the store side, LA664, Zen 3, and Golden Cove are all the same at 2 scalar stores per cycle whereas the LA464 can only handle one store per cycle.

LA664 can handle two 256-bit vector accesses per cycle. These can be any combination of loads and stores.
Memory Ordering
Once addresses are generated, the load/store unit has to ensure memory accesses appear to execute in program order. Loads may have to get their results from a prior store. Like the prior 3A5000, 3A6000 can handle cases where a load is contained within a prior store with about 7 cycle latency. Partial overlap cases incur a 14 cycle penalty, probably with the load getting blocked until the store retires and writes back to L1D.
Zen 2 has the same 7 cycle forwarding latency and 14 cycle partial overlap penalty. But Zen 2 can handle forwarding across a 64B cacheline with just an extra cycle penalty, while Loongson struggles with that case. Since Zen 2 can run at much higher clock speeds than LA664, the 7 cycle forwarding latency feels a bit long. Goldmont Plus targets frequencies in the upper 2 GHz range, and has 5 cycle store forwarding latency with a 10 cycle failure case.

LA664’s store forwarding behavior looks a lot like its predecessor. But LA664 gets rid of the nasty 10 cycle penalty for a misaligned store, and brings that down to just 3 cycles. It’s slightly better than Zen 2, which takes 2 to 5 cycles for a misaligned store.

Store forwarding across a 64B boundary is still handled poorly, but the penalty has gone down from 31 cycles to a more tolerable 21.
Cache and Memory Access
A good cache and memory hierarchy is vital to keeping any modern high performance CPU fed. The 3A6000 retains a similar cache hierarchy but with minor improvements throughout.

Since Loongson wasn’t able to manage a clock speed increase, they decreased latency by cutting pipeline stages in the cache access paths.
Latency
L1D latency goes down from four to three cycles. I think low clocked CPUs should be targeting 3 cycle L1D latency, and it’s great to see that on 3A6000.

A lot of modern CPUs use the L2 as a mid-level cache to insulate L1 misses from the relatively high latency L3. 3A6000 continues to use a 256 KB L2 cache like older Intel architectures. Recent AMD and Intel CPUs have been trending towards using larger L2 caches. Zen 4 moves to a 1 MB L2 cache, while Intel’s Raptor Lake opts for huge 2 MB L2. Even though Loongson wasn’t able to implement a larger L2, they did manage to bring latency down from 14 to 12 cycles. The L1 to L2 path likely only saw a single pipeline stage reduction, assuming L1 handle hits and misses with the same speed.
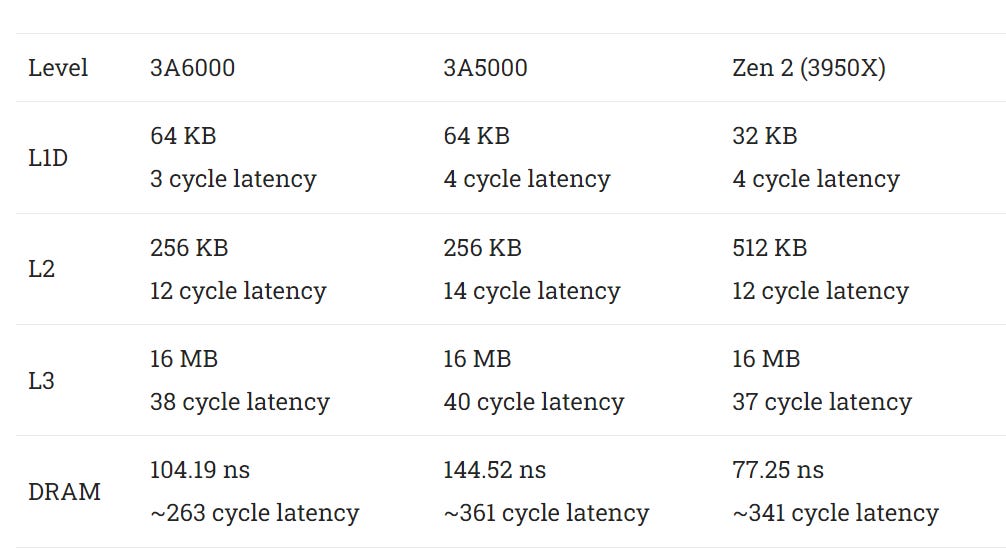
Zen 2, 3A6000, and 3A5000 all feature a large 16 MB L3 cache shared by four cores in a cluster. 3A6000 reduces L3 latency by a couple cycles, though that’s likely because checking the L2 got two cycles faster.
Finally, DRAM latency improves from 144 ns to 104 ns. 3A5000 had a horrible DDR4 controller. It was only “saved” because its low clock speed meant the latency in cycle counts was similar, meaning that it had a minor impact on IPC. 3A6000 gets a much improved memory controller. 104 ns still isn’t great, but it brings latency in cycle count terms below what we see on the higher clocked 3950X. Thus 3A6000 at least mitigates some of its low clock speed disadvantage by losing fewer cycles to DRAM access latency. Still, 104 ns is not great for a DDR4-2666 setup on a monolithic chip.

While 3A6000 has competitive cycle count latencies, we have to consider actual latency because Loongson can’t clock its CPU anywhere near what modern AMD and Intel CPUs run at. And that doesn’t paint a rosy picture for LA664. It’s slower at every cache level including L1. That explains why LA664 consistently loses to Zen 2, despite having more reordering capacity and higher IPC.
Bandwidth
Bandwidth can influence performance especially for vectorized, multithreaded applications. The 3A6000 largely inherits its predecessor’s memory hierarchy, but Loongson has again made improvements at various points.

3A5000 already had similar per-cycle L1D bandwidth to Intel’s Skylake or AMD’s Zen 2. 3A6000 improves by doubling write bandwidth. Basically, 3A6000’s L1D can service two 256-bit accesses per cycle with any combination of reads or writes.

As a result, 3A6000 has impressive L1D write bandwidth despite its low clock speed. LA664 thus joins Golden Cove as the only consumer cores with 512 bytes per cycle of store bandwidth.
LA664’s 256 KB L2 basically performs like its predecessor did with 21-22 bytes per cycle of read bandwidth. Write bandwidth is identical. Thus 3A6000 still has lower per-cycle L2 bandwidth than any of AMD or Intel’s recent CPUs. The gap gets particularly wide against Intel CPUs, which have a 64 byte per cycle path to L2.

At L3, LA664 enjoys a 33% bandwidth increase over its predecessor. 18.7 bytes per cycle from L3 lets Loongson compare well against older Intel CPUs, but AMD’s exceptionally strong L3 implementation still pulls ahead.

Designing a shared cache brings in an extra dimension of challenge because cache bandwidth has to scale to serve multiple clients. The 3A6000 can give each core 16.55 bytes per cycle when all hardware threads are loaded. That’s only a bit less than what one core can get without contention from other cores, and a very good showing overall. The older 3A5000 could only give each core just over 10 bytes per cycle with all four cores loaded, compared to 13.7 bytes per cycle with a single core active. That suggests contention in the 3A5000’s L3 complex, which 3A6000 largely solves. AMD again delivers exceptional L3 bandwidth even when multiple cores are hitting the cache, with over 24 bytes per cycle per core.

Loongson’s 3A5000 had a horrifyingly bad DDR4 controller. The 3A6000 thankfully has a much better one. It technically supports DDR4-3200, but we weren’t able to get a stable boot with that DRAM speed when running both channels. When equipped with dual-channel DDR4-2666, the 3A6000 achieves DRAM read bandwidth roughly on par with the Core i5-6600K. That chip’s first generation DDR4 controller could only handle DDR4-2133 with perfect stability (at least on my copy), but still manages better DRAM read bandwidth than the 3A6000 does with faster memory.

Even though the 3A6000 has mediocre DRAM read performance, it does have a trick up its sleeve with writes. Loongson is probably avoiding read-for-ownership requests when it detects cachelines being overwritten without any dependency on its prior contents. That could help for certain access patterns, but benefits will likely be limited because programs tend to have far more reads than writes overall.
Core to Core Latency
This test uses atomic compare-and-exchange operations to bounce values between cores.

Loongson’s performance doesn’t bring any surprises, which is a good thing.
Final Words
Engineers at Loongson have a lot to be proud of. Creating a branch predictor on par with Zen 2’s isn’t easy, and that achievement is made all the more impressive considering where Loongson was with 3A5000. Similarly, SMT is very difficult to get right. Loongson managed to do both while dramatically scaling up the 3A5000’s out-of-order engine and fixing its DDR4 controller. The resulting massive performance gain puts LA664 on par with Zen 1, at least when each core only has a single hardware thread active.
The 3A6000 is part of China’s efforts to make its economy less dependent on foreign CPUs. In that respect, 3A6000 is a good step forward. Zen 1 is still quite serviceable today, so Chinese consumers would likely find the 3A6000’s performance tolerable for lightweight everyday tasks. Loongson’s software ecosystem will have a far bigger impact on the chip’s usability than its performance.
But Loongson has a secondary goal of being a world class CPU maker alongside western companies like Intel and AMD. They still have a long way to go in that respect. Zen 1 level single threaded performance is commendable. But we have to remember Zen 1 gained market share against Intel because it brought affordable 6 and 8 core parts into consumer platforms, not because it could win core for core against Skylake. The 3A6000 is just a quad core part, and thus lacks Zen 1’s biggest strength.

Loongson also compares 3A6000 to Intel’s Core i3-10100, a quad core Skylake part with 6 MB of cache and a 4.3 GHz boost clock. While nominally a 10th generation part, the i3-10100 is more comparable to the Core i7-6700K of 2015. Intel’s 10th generation is better known for bringing 10 core CPUs into the company’s consumer lineup, with 6 and 8 core parts making up the midrange. Besides more cores, parts like the i5-10600K and i7-10700K enjoy higher boost clocks. 3A6000 would not be competitive against those parts. Loongson would also struggle against Zen 2 offerings from the same era. We already saw the 3950X comfortably pull away from the 3A6000 in core for core tests. That gap will only widen when more than four Zen 2 cores come into play.
Today, Intel’s Golden Cove derivatives and AMD’s Zen 4 enjoy an even larger lead over 3A6000. Quad core parts have largely disappeared from both AMD and Intel’s consumer lineups. Loongson’s 3A6000 might be the most promising CPU we’ve seen from China, and is far more exciting to dig through than a bungled attempt to iterate off A72. But Loongson’s engineers still have their work cut out for them. We look forward to seeing what they pull off next.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.