
Sandy Bridge: Setting Intel’s Modern Foundation

Processor companies typically iterate off proven designs, and for good reason. Changing too many things at once introduces a lot of risk. A lot of changing parts makes it hard to get a good picture of overall performance, so it also makes tuning difficult. Pentium 4 and Bulldozer made clean breaks from prior architectures, and both were unsuccessful designs. But sometimes, making a clean break does pay off.
Sandy Bridge is one such case. It inherited architectural features from Intel’s prior P6 and Netburst architectures, but can’t be considered a member of either line. Unlike Netburst, Sandy Bridge was so successful that Intel’s high performance cores to this day can trace their lineage to back to it. In the early 2010s, Sandy Bridge was so successful that Intel went completely unchallenged in the high end CPU market. And as a testament to the architecture’s solid design, Sandy Bridge CPUs still deliver enough performance to remain usable across a range of everyday tasks.
Block Diagram
Sandy Bridge is a four-wide, out-of-order architecture with three ALU ports and two AGU ports. The same applies to prior generations from the P6 family. Core 2 (Merom) and the first generation Core i7/5/3 CPUs (Nehalem) were also four-wide, and have the same execution port count. But core width and execution resources are one thing, and feeding them is another. Sandy Bridge is far better at keeping itself fed, thanks to improvements throughout the pipeline and cache hierarchy.
Frontend: Branch Prediction
Branch prediction is vital to CPU performance, especially for out-of-order CPUs that can speculate far ahead of a branch. Sandy Bridge dramatically advances branch predictor performance compared to Nehalem, and can recognize much longer patterns. According to Microprocessor Report (MPR), Sandy Bridge does not use classic 2-bit counters for its history table. Instead, entries use 1-bit counters, with a “confidence” bit shared across multiple entries. Thus, Sandy Bridge was able to implement a larger history table with the same amount storage.

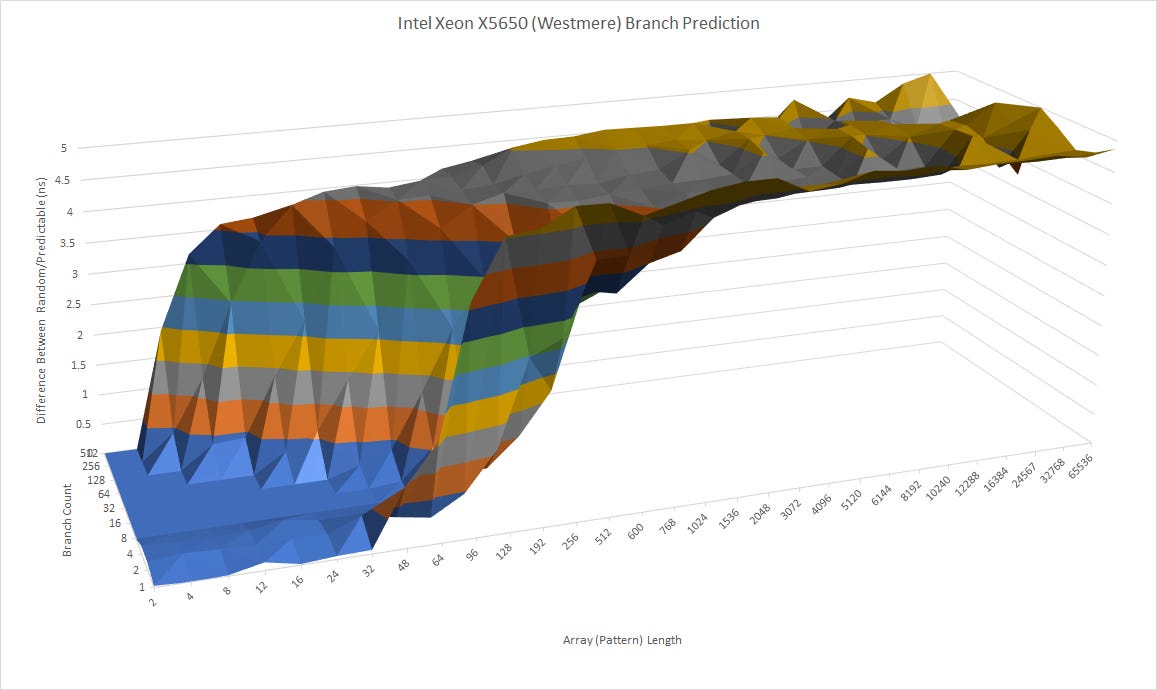
A larger history table lets Sandy Bridge recognize longer patterns when there are a few difficult to predict branches, and avoid destructive aliasing when a lot of branches are in play. Intel made a large improvement in direction prediction, and that’s important because Sandy Bridge can speculate farther than Nehalem can.
Branch Target Tracking
Intel made similar optimizations to the branch target buffer (BTB), a structure that remembers where branches went so the branch predictor can steer the frontend with minimal delay. Instead of directly holding branch targets, Sandy Bridge stores branch offsets and adds those to the current program counter to calculate the branch target. Most branches jump short distances, so most BTB entries can be small. MPR further states that Nehalem’s BTB had 64 bit entries, which I find very unlikely. x86-64 virtual addresses are only 48 bits wide, and Nehalem uses 40-bit physical addressing. Using 64-bits to store a branch target would be an exercise in stupidity because the upper 16 bits would always be zero. Maybe 64 bits refers to the total size of the BTB entry, including tag and state bits.
Compared to Nehalem, Sandy Bridge doubles the BTB capacity from 2048 entries to 4096 entries. Intel accomplished this doubling of capacity with no penalty, which is quite an impressive feat. AMD’s Bulldozer increased BTB capacity from 2048 entries in K10 to 5120 entries, but had to do so by adding a slower BTB level.

Sandy Bridge’s main BTB has 2 cycles of latency. That matches Bulldozer’s 512 entry L1 BTB, and is much faster than Bulldozer’s 5 cycle L2 BTB. However, 2 cycle latency still means the frontend loses a cycle after a taken branch. To mitigate this, Sandy Bridge can handle up to eight branches with single cycle latency, possibly by using a very fast L0 BTB. AMD didn’t get similar capability until Zen released in 2017.
Interestingly, I was unable to reach full BTB capacity. However, Matt Godbolt has run extensive tests to measure BTB capacity on Ivy Bridge (the 22nm die shrink of Sandy Bridge), and concluded that the BTB has 4096 entries. Furthermore, he measured 2048 BTB entries on Nehalem.
Return Stack
Returns are used to exit from a function back to the calling code, and are quite common. They’re also easy to predict, because returns will almost always match up with a function call. CPUs take advantage of this by using a stack to predict returns. Sandy Bridge’s return stack has 16 entries, which should be adequate for most cases. Bulldozer has a larger 24 entry return stack. AMD can cope better with deeply nested function calls, though there’s probably diminishing returns to increasing return stack depth.
Indirect Branch Prediction
Returns are a special case of indirect branches, or branches that go to multiple targets. Predicting indirect branch destinations is quite a bit more difficult, but also important because they’re commonly used for method calls in object oriented languages.

Sandy Bridge’s indirect predictor can track up to 128 targets, achieved with 64 branches going to two targets each. For a single branch, the predictor can pick between up to 24 targets.
Frontend: Fetch and Decode
Once the branch predictor has determined where to go, the frontend has to bring instructions into the core. Sandy Bridge’s frontend inherits features from Nehalem, but gets a new 1536 entry, 8-way micro-op cache. The micro-op cache holds decoded instructions, allowing the core to skip the traditional fetch and decode path. In that sense, it’s similar to Netburst’s trace cache. Both architectures can deliver instructions with lower power and lower latency when feeding the pipeline from the micro-op or trace cache. But Sandy Bridge doesn’t try to cache traces. Rather, micro-op cache lines directly correspond to 32-byte aligned memory regions. Compared to Netburst, Sandy Bridge gets better caching efficiency, because Netburst’s trace cache might store the same instruction many times to improve fetch bandwidth around taken branches.

But Sandy Bridge’s micro-op cache is still optimized for high speed and low power, rather than caching efficiency. It’s virtually addressed, meaning that program addresses don’t have to be translated to do a micro-op cache lookup. To maintain consistency between virtual and physical addresses (i.e. handle cases where the OS changes mappings between virtual and physical addresses), the L1 instruction cache and instruction TLB (iTLB) are inclusive of the micro-op cache. An iTLB miss implies a micro-op cache miss, and iTLB evictions can flush the micro-op cache. On top of that, some instruction patterns can’t be filled into the micro-op cache:

Therefore, Sandy Bridge’s micro-op cache augments the traditional fetch and decode mechanism instead of replacing it. Because micro-op cache hitrate isn’t expected to be as good as with a traditional L1i cache, the micro-op cache is used in a way that minimizes penalties when code spills out of it. Intel only transitions to the micro-op cache after a branch, meaning the frontend isn’t constantly checking the micro-op cache tags and wasting power when hitrate may be low.
Compared to its primary competitors and prior Intel architectures, Sandy Bridge can achieve excellent performance with small instruction footprints but relatively long instruction lengths. Dense compute kernels come to mind here, because they’ll use longer AVX instructions executing in small loops.

Once code spills out of the micro-op cache, frontend throughput takes a sharp drop. However, the L1 instruction cache can still provide enough bandwidth if instructions are around 4 bytes. Integer code typically has average instruction lengths a bit below 4 bytes.

If code spills out of the L1i, instruction throughput takes a sharp drop. But while it’s a step behind modern chips, it compares well to its competition. Bulldozer struggles even more if it has to fetch code from L2, though the large L1i should reduce how often that happens.

In the end, Sandy Bridge has a very complex frontend compared to prior Intel architectures, or indeed anything else of its time. The core can incredibly feed its pipeline from four different sources. At first, that sounds like a non-intuitive and complex solution. But imitation and longevity are the sincerest forms of flattery for microarchitecture design. Today, ARM and AMD use similar frontend strategies in their high performance cores, which speaks to the strength of Sandy Bridge’s design.
Rename and Allocate
After instructions have been converted into micro-ops, backend resources have to be allocated to track them and enable out-of-order execution. This stage is called the renamer, because it performs register renaming to break false dependencies. It’s also a convenient place to pull more tricks that expose additional parallelism to the backend. For example, operations that always result in zero can be set to have no dependencies. Register to register copies can be eliminated by manipulating the register alias tables. Sandy Bridge recognizes zeroing idioms, but Intel was not able to implement move elimination. That would have to wait until Ivy Bridge.
Execution Engine
Sandy Bridge’s out-of-order execution engine is a fresh design. At a high level, it’s Netburst but bigger and less stupid. By that, I mean it uses a PRF based execution scheme where data values are stored in physical register flies, and pointers to register file entries get moved around instead of the values themselves. Contrast that with P6’s ROB based execution scheme, which stores register values in the ROB. When an instruction retires, P6 copies its result from the ROB to a retired register file. Apparently, P6 also stored input values in its scheduler. That may have simplified design because all the info needed to execute a micro-op can come from the scheduler, but bloats scheduler size.

These inefficiencies were probably fine on early P6 variants, where the largest register values were 80-bits wide. Nehalem’s 128-bit SSE registers were pushing things a bit, but growing transistor budgets and process improvements let it get by. Sandy Bridge is a different story. 256-bit AVX registers are no joke, and Intel needed to move those giant values around as little as possible. By going to a PRF based scheme, Intel was able to provide a full width AVX implementation while also greatly increasing reordering capacity.
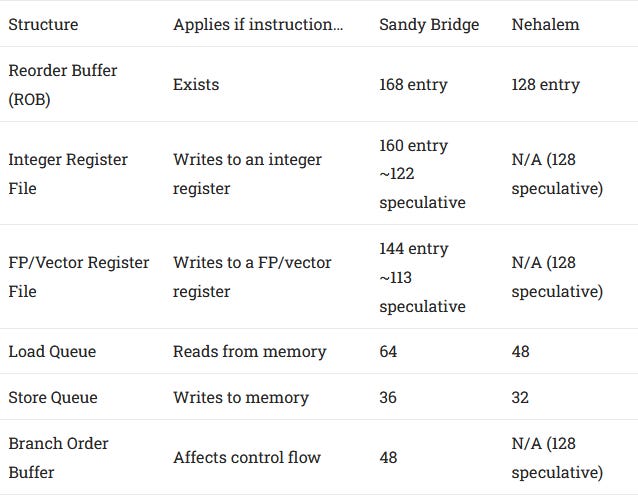
Intel’s PRF implementation has some quirks as well. Apparently, Sandy Bridge has a Physical Register Reclaim Table (PRRT) structure in addition to separate freelists for each register file. The PRRT is responsible for telling the retirement stage what register (if any) can be reclaimed when an instruction retires, but notably doesn’t have enough entries to cover the entire ROB.

Sandy Bridge can therefore have its reordering capacity limited by how many total registers it can allocate, even if the relevant register file has free entries.
Execution Units
Once the scheduler has determined that a micro-op is ready for execution, it’s sent to Sandy Bridge’s six execution ports. It’s easier to think of this as five ports (three for math, two for memory), because a sixth port is only used to handle stores. Stores on Intel CPUs use both an AGU port and a store data port, so the store data port doesn’t allow higher instruction throughput.
Execution units are generally well distributed across the ports, but there are weak points compared to newer CPUs. That especially applies for vector and floating point execution. If code has a lot of shuffle operations, port 5 can see heavy load because it has to handle all vector shuffles and branches.
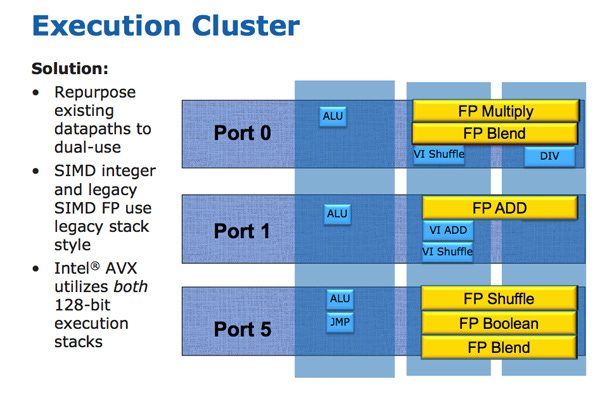
Floating point workloads dominated by adds or multiplies (but not a roughly even mix of both) could see port bottlenecks on ports 1 and 0, respectively. That’s really only a disadvantage compared to more modern architectures, as prior generations of Intel CPUs had similar limitations.
Memory Execution
Operations that access memory are sent down Sandy Bridge’s two address generation pipelines. Prior Intel architectures had specialized AGU pipes, with one for loads and the other for stores. Sandy Bridge uses a more flexible setup where both pipes can handle either loads or stores. Loads tend to be far more common than stores, so Sandy Bridge should see far less contention on the AGU ports.
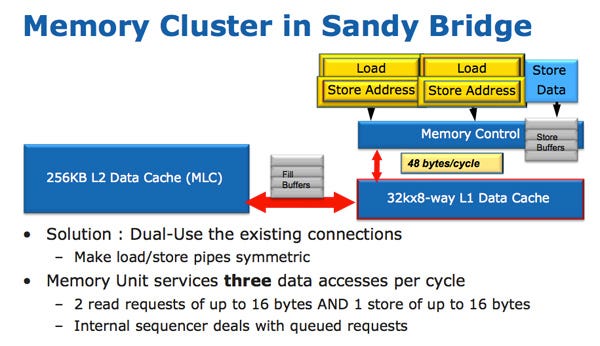
However, AGU throughput is still a stumbling block for Sandy Bridge. Per-cycle, the L1D can theoretically service three accesses, but the AGUs can only provide two addresses. In 2013, Intel’s Haswell introduced a triple AGU setup, letting it sustain 3 memory operations per cycle. AMD did the same in 2019 with Zen 2. It’s not a big deal but newer CPUs do better.
Memory Disambiguation, and Load/Store Penalites
After addresses are calculated, the load/store unit has to make sure memory dependencies are satisfied. Loads that overlap with earlier in-flight stores have to get their data forwarded, but checking for partial overlaps can be complicated. Nehalem had a very sophisticated comparison mechanism, and could handle all cases where the store is completely contained within a later load. The same applies to Sandy Bridge, but the check appears to be done in two stages.

First, Sandy Bridge does a quick check to see if accesses overlap the same 4 byte aligned region. It only does a more thorough check if there is an overlap. Successful store forwarding has a latency of 5-6 cycles, while partial overlap cases take 17-18 cycles, or 24-25 cycles if they cross a cacheline boundary. Store forwarding is a lot less sophisticated for vector accesses. Sandy Bridge can only forward the lower or upper half of a 128-bit store, and does so with a latency of 7-8 cycles.
Address Translation and Paging
All modern operating systems rely on virtual memory to keep misbehaving processes from tripping over each other or bringing down the entire system. Virtual memory requires virtual program-visible addresses to be translated to physical addresses. Sandy Bridge uses a two-level cache of address translations to speed this up. First, a 64 entry DTLB can provide translations without penalty. If the L1 DTLB is missed, Sandy Bridge can get the translation from a 1024 entry L2 TLB, with an additional 7 cycles of latency.
Address translations get messy if an access crosses a page boundary, because the underlying data might be very far apart in physical memory. On Sandy Bridge, a split-page load costs 36 cycles, while a split-page store costs 25 cycles. Forwarding doesn’t work across page boundaries, where you can see a 36 cycle penalty if the store spans pages. If both the load and store cross a page boundary, the penalty goes to 53 cycles. Modern CPUs improve on these penalties, but Sandy Bridge already turns in a far better performance than its AMD competition.
Cache Performance
Intel standardized on a triple-level caching setup starting with Nehalem. Sandy Bridge carries the high level caching scheme forward, but with important improvements. Starting at L1, the improved AGU setup gives Sandy Bridge twice as much load bandwidth as Nehalem. L2 bandwidth also improves, though it’s nowhere near the 32 bytes per cycle that Sandy Bridge should be theoretically capable of.

At L3, we see a slight bandwidth advantage for Sandy Bridge. The Xeon X5650 and E5-1650 both serve their cores with 12 MB of L3 cache arranged into six slices, but do so very differently. Westmere and Nehalem use a centralized Global Queue (GQ) in front of the L3 cache. All L3 request tracking can happen at the GQ so that approach is probably easier to implement and verify. But it’s not scalable.

Higher core counts mean more L3 and memory requests in flight, so the GQ needs more entries to cope. A larger GQ means more requests to scan when making decisions on request priority2. All of this has to be handled with low latency. The GQ is not ideal for that either, because every request has to go through the centralized queue in the middle of the chip, even if the L3 slice holding the relevant data is quite close to the requesting core.
Sandy Bridge ditches the GQ in favor of a divide-and-conquer approach. L3 lookup and request tracking functionality gets distributed across the L3 slices, which are connected via a ring bus. The request scheduler at each L3 slice can be smaller than the GQ, and can run at core clocks. In the end, the ring bus delivers massive bandwidth advantages:

Even under heavy load, the E5-1650 (Sandy Bridge) can provide more than 9 bytes per cycle of bandwidth to each of its six cores. Each of the X5650’s cores in contrast can only average 4.7 bytes per cycle. Sandy Bridge’s advantage extends past bandwidth. Latency improves because requests can take a more direct route to the destination slice, instead of always going through GQ in the center of the die. Simpler request arbiters probably help latency too.

In terms of core clocks, Sandy Bridge drops latency by about 7 cycles. That’s already a good improvement. But we can only capture the magnitude of Sandy Bridge’s progress when we look at actual latency. 10.3 ns is an excellent figure for a 12 MB cache. I really have to give it to Intel’s engineers here because they delivered a massive leap in L3 performance even when their prior design would have had no problems competing against AMD.

However, Sandy Bridge doesn’t improve latency across the board. L2 latency regresses by two cycles compared to Nehalem, though the E5-1650’s higher clock speed means actual latency is very similar. 12 cycle L2 latency is very acceptable in any case.
Cache Coherency Performance
L3 performance is an excellent way to measure Sandy Bridge’s interconnect performance, because L3 traffic makes up most of the traffic going across the ring bus. Another way to check interconnect performance is testing how long it takes to bounce data between pairs of cores. While this form of traffic is quite rare and therefore less optimized, it can show the interconnect topology.

Sandy Bridge sees slightly varying core to core latencies, depending on how far cores are from the L3 slice that owns the cache slice. On Westmere and Nehalem, all requests flow through a centralized arbiter. Latencies are more uniform, and are uniformly higher. The E5-1650’s worst case is better than the X5650’s best case.
Alongside non-contested L3 performance, Sandy Bridge’s core-to-core latency performance demonstrates the excellence of its ring bus design. Again, imitation and longevity are the sincerest forms of flattery for CPU features. Today, Intel continues to use a ring bus in client CPUs, and AMD has done the same (starting with Zen 3).
Final Words
Sandy Bridge is now more than a decade old, but Intel architectures today can still trace their origins to iterative changes built on top of Sandy Bridge’s base. As another compliment to Sandy Bridge, its concepts have shown up in successful architectures outside of Intel. AMD’s Zen line uses a micro-op cache and a distributed L3 design, though implementation details differ. Micro-op caches also appear on ARM’s latest high performance designs.
Today, Sandy Bridge remains surprisingly usable, even if more modern CPUs beat it into the ground in head-to-head benchmarking. That’s because it does the important things right. Its branch predictor performs well. Out-of-order buffers are well balanced, and the pipeline in general has few penalties. Caches have low latency and adequate bandwidth. Modern CPUs do better in most of those categories, but are often chasing diminishing returns. In short, there’s not a lot that Sandy Bridge did wrong.
When Sandy Bridge does fall short compared to modern CPUs, it’s generally in specific categories of applications. For example, its execution port count looks absolutely anemic compared to CPUs just a generation later. But feeding the execution resources is more important than having a lot of them, so having fewer ports isn’t a big deal. Sandy Bridge also isn’t as wide as newer CPUs, but again core width is not as important as feeding that width.
Most impressively, Intel made enormous strides without serious competition. A slightly improved Nehalem would have been enough to beat AMD’s Bulldozer. Instead, Intel created a fresh design that left AMD completely in the dust. Then, Intel made iterative improvements that kept the company well ahead of any competition. When looking back at Sandy Bridge and the years after its release, I can’t help but miss the old Intel. Intel in the early 2010s was bold and confident, introducing performance and power efficiency improvements on a steady pace. Today’s Intel barely keeps its footing against a resurgent AMD. That said, Intel has a tradition of learning from setbacks and coming back stronger. They recovered from the Pentium FDIV bug and grew to dominate the PC market. They recovered from the misstep of Netburst to deliver Core 2, and then used what they learned from both architecture lines to create Sandy Bridge. Hopefully, Intel will have another Sandy Bridge or Core 2 moment in the years to come.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.
References
Linley Gwennap, Sandy Bridge Spans Generations, Microprocessor Report
The Uncore: A Modular Approach to Feeding the HIgh-Performance Cores, Intel Technology Journal, Volume 14, Issue 3