
Van Gogh, AMD’s Steam Deck APU

Zen 2’s launch was a defining moment for AMD. For the first time in many, many years, AMD’s single thread performance could go head to head with Intel’s best. Zen 2 also started a trend where AMD brought up to 16 cores to desktop CPUs, giving consumers very strong multithreaded performance without having to buy HEDT platforms.
But Zen 2 was also flexible and did a very good job of scaling down to lower power targets. That was especially true when Zen 2 cores were implemented in more power efficient monolithic dies. Possibly because of that, the Zen 2 architecture went on to serve in new products even after Zen 3’s late 2020 launch. In 2021, Lucienne products like the Ryzen 7 5700U used Zen 2 cores in an updated platform. Mendocino launched in 2022 to target low power laptops, with Zen 2 cores ported to TSMC’s 6 nm process. Van Gogh is yet another example. It’s a rather unique product that combines RDNA 2 with four Zen 2 cores on TSMC’s 7 nm process.

Unlike Lucienne and Medocino, Van Gogh isn’t a general purpose laptop chip. It only shows up in the Steam Deck, an ultraportable gaming console with a form factor that’s vaguely comparable to Nintendo’s Switch. Of course, the Steam Deck is meant to run PC games, which can be significantly more demanding. Unlike its Zen 2 cousins, the Van Gogh chip in the Steam Deck didn’t get a proper name. It instead reports itself as “AMD Custom APU 0405”.
Configuration
The Steam Deck has 16 GB of LPDDR5: two Samsung chips with 8 GB of capacity each. They’re arranged in four 32-bit channels and run at 5500 MT/s, which should give 88 GB/s of theoretical bandwidth. The motherboard is called “Valve Jupiter”. It connects the APU to an x4 M.2 slot, and provides x1 PCIe links to a micro-sd card controller and a Realtek 8822CE WiFI card.

Power to the APU is provided by three VRM stages, controlled by a MP2845. Two of the stages are marked 8690 2823 B, while a third is marked 8690 3000 C. The VRM is possibly split into a two-stage component and a separate single-stage one. Therefore, the VRM is rather weak, but that’s not a huge deal considering the APU appears to be capped at 16 W. That power budget is flexibly allocated between the CPU and GPU. For example, a GPU-bound sequence could see the GPU pulling over 10 W, while the CPU side gets squished below base clock and draws 2-3 W. The opposite applies for a CPU-only workload.
This sort of flexible power allocation can work well when a game is primarily CPU bound or GPU bound. But it does leave performance on the table if you’re trying to use both the CPU and GPU together to maximize compute throughput. Typically, you see that happen with compute applications, like renderers and photo processing applications. The Steam Deck doesn’t primarily target that, so it should be fine unless a game pegs both the CPU and GPU at the same time.
CPU Side
Van Gogh features four Zen 2 cores in a single cluster (CCX), with a 3.5 GHz boost clock and 2.8 GHz base clock. I’m going to focus on system level stuff here, and cover Zen 2’s core architecture separately in another article. From brief testing I didn’t see any differences from a normal Zen 2 core. There’s no cut down FPU like on the PS5, for example.

A core-to-core latency test confirms that there’s a single CCD, with a quad core, eight thread configuration.
Caching
Like Renoir, Van Gogh’s CCX only has 4 MB of L3 cache. Desktop and server Zen 2 variants feature 16 MB of L3 cache per CCX, which helps insulate the cores from slow memory and generally improves performance.
Valve is doing something funny in their OS, because the L3 is basically missing from a latency test with default settings. Setting the scaling governor to performance rather than the default schedutil makes something resembling a L3 show up, but performance is still very poor. L3 performance is reasonable under Windows, indicating it’s not a defect in the APU.
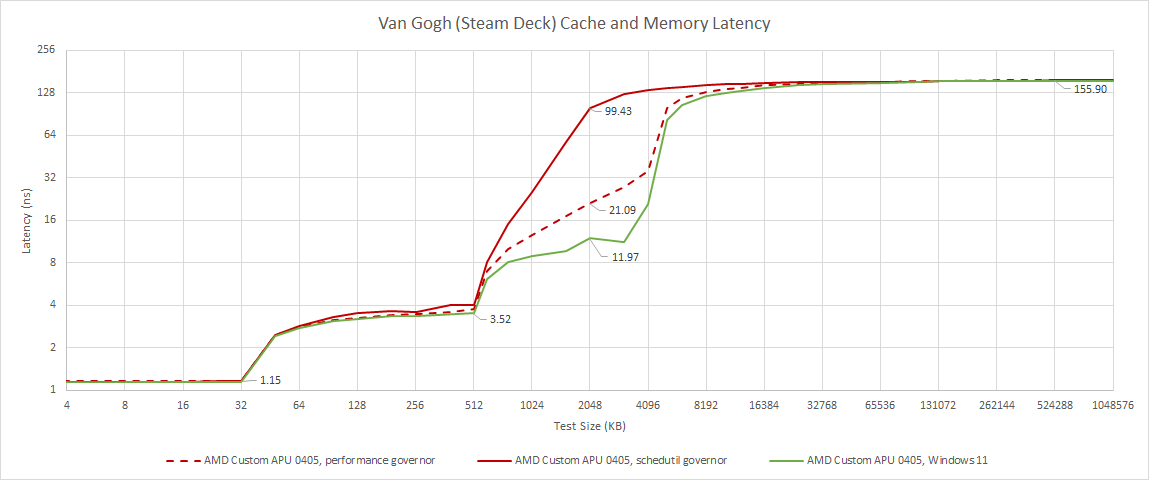
Van Gogh’s L1 and L2 caches perform just as you would expect from any Zen 2 CPU. Like with Renoir, we see 4 cycles of L1D latency, and 12 cycles of L2 latency. Both mobile chips see a big L3 capacity deficit compared to a high end desktop Zen 2 implementation.

A small L3 hurts Renoir, but Van Gogh sees a special level of pain because LPDDR5 latency is abysmal. Even servers these days don’t take 150 ns to get data from memory. Unlike the L3, results remained consistently poor even in Windows 11. We’re probably seeing a serious issue with the memory controller rather than OS power saving weirdness.

The Ryzen 7 4800H laptop tested was equipped with DDR4-3200 22-22-22-52. Those JEDEC timings aren’t as tight as what you might find on a typical desktop DDR4 kit, but the 4800H still shows off a much better latency result than Van Gogh. I guess something had to give for the L part of LPDDR5.
Bandwidth
L3 issues seem to be gone with a bandwidth test, with similar results using Windows or Linux. We see over 200 GB/s of L3 bandwidth with an all-thread load. Bandwidth therefore looks fine, even if it’s a bit lower than that of other Zen 2 implementations because of clock speed differences.

However, LPDDR5 again turns in a disappointing performance. Certainly, a variety of factors mean that getting full theoretical bandwidth out of any DRAM configuration is a pipe dream. For example, you’ll lose memory controller cycles from read-to-write turnarounds and page misses. But 25 GB/s is on the wrong planet.
I expected better performance out of a 128-bit LPDDR5-5500 setup. The chips themselves are rated for 6400 MT/s, meaning that theoretical memory bandwidth is totally wasted from the CPU side.
To put more perspective into just how bad this is, Renoir’s DDR4-3200 setup beats Van Gogh’s by a massive margin. That applies even when I used process affinity to limit my test to a single CCX. 25 GB/s is something out of the early DDR4 days. For example, a Core i5-6600K can pull 27 GB/s from a dual channel DDR4-2133 setup.

The LPDDR5 setup therefore saddles the CPU with garbage memory latency, while providing bandwidth on par with a DDR4 setup out of late 2015. It’s not a huge step up from a good DDR3 setup either. All that is made worse by the CPU’s small L3 cache, which means the cores are less insulated from memory than they would be on a desktop or server Zen 2 implementation.
For even more perspective, we can look at memory bandwidth usage in Cyberpunk 2077. The game was run with raytracing off, allowing framerates to hover around 100 FPS. I’m using undocumented performance counters, but I’ve tested by pulling a known amount of data from memory and checking to make sure counts are reasonable.

Even desktop Zen 2 with 16 MB of L3 would find itself needing more than 25 GB/s. Less L3 capacity means even higher memory bandwidth demand. Van Gogh is clearly not optimized to get the most out of its CPU cores. It’s starting to feel like a smaller console APU, where engineering effort is focused on the GPU side, rather than the CPU.
Clock Ramp Behavior
CPUs don’t run at maximum clock all the time, and that especially applies for a mobile device. Instead, they increase clocks in response to load. That clock ramping process can take time. Generally most client devices go to maximum clock as fast as possible to deliver high responsiveness. The Steam Deck does not do this. Clock speeds start at 1.4 GHz, and then reach 1.7 GHz in 0.27 milliseconds. That’s a good start and shows the APU can command clock changes quite quickly. However, it sits at 1.7 GHz for hundreds of milliseconds before slowly stepping up clock speeds. It doesn’t reach maximum clocks until nearly a second.

This kind of boost behavior is terrible for a client device. It’s going to feel a lot less responsive than other Zen 2 systems. For comparison, Renoir reaches its maximum boost clock in 9.35 ms. Even older CPUs like Piledriver and Haswell can reach maximum clocks in less than 100 ms, which makes me think this boost policy is deliberate. Behavior is similarly bad on both Windows and SteamOS. Perhaps Valve did so in order to extend battery life at the expense of responsiveness. After all, the Steam Deck is designed for long running tasks like games. Web browsing is not a primary use case.
Van Gogh’s GPU
Valve’s Steam Deck is a gaming-first device, so the GPU deserves attention. Like the chip as a whole, AMD did not give the GPU a fancy name. If you query it from OpenCL or Vulkan, it tells you it’s the AMD Custom GPU 0405. This is apparently an RDNA 2 derived GPU with 512 FP32 lanes, or 4 WGPs. It runs at up to 1.6 GHz, which is a very low clock speed for a RDNA 2 GPU. For perspective, the RX 6900 XT can run at 1.7 GHz with an incredibly low 0.8 V core voltage. Low power definitely takes precedence over absolute performance, or even hitting the architecture’s efficiency sweet spot. General software support was not a priority either. To make my life hard, the AMD Custom GPU 405 lacks OpenCL support. So, I’m using Nemes’s Vulkan-based test suite.
The AMD Custom GPU 0405 has a RDNA style cache setup, meaning it has an extra cache level compared to Renoir’s Vega iGPU. There’s 16 KB first-level vector and scalar caches, backed by a 128 KB L1. Like Renoir, Van Gogh uses a disproportionately large 1 MB L2 cache to insulate the GPU from DRAM. If we maintained the same L2 cache to compute ratio as AMD’s RX 6900 XT, a GPU with four WGPs would have less than 512 KB of L2.
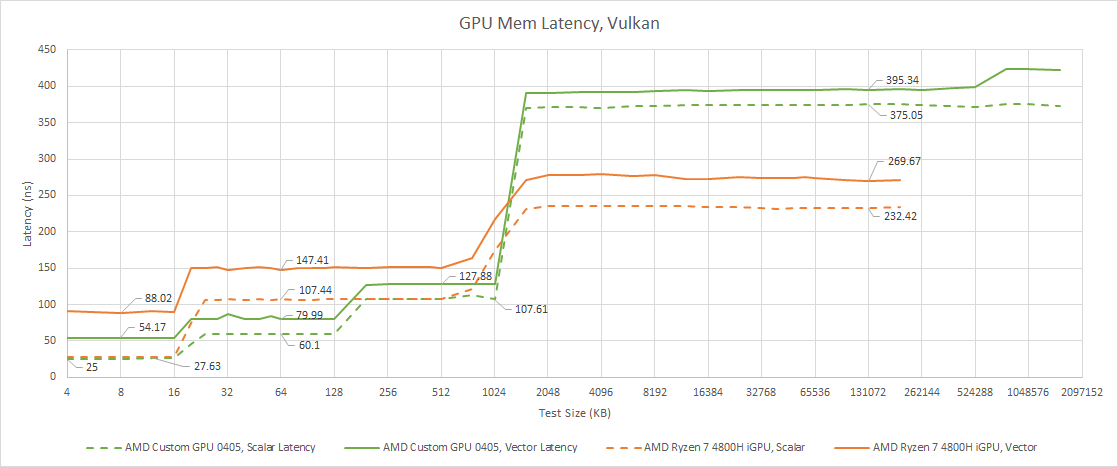
RDNA’s architectural advantages are on full display. Vector memory access latency is much better than Vega’s. Vega is more competitive from the scalar side, with nearly identical scalar cache access latency. But RDNA’s 128 KB L1 should still give it an edge because both iGPUs have similar L2 latency. Again, that’s impressive for Van Gogh because it’s able to maintain the same L2 latency while getting the advantage of a 128 KB L1 mid-level cache.
DRAM latency is again terrible. RDNA 2’s memory latency typically compares well to GCN-based architectures. But LPDDR5 latency is a nonstop shitshow, and the GPU side is not immune. Thankfully, bandwidth is much better. With a GPU bandwidth test, the LPDDR5 controller finally redeems itself and achieves something close to what it should be capable of on paper. With over 70 GB/s of bandwidth, the Custom GPU 0405 gets a massive bandwidth lead over Renoir’s iGPU. That lines up with Van Gogh being a gaming focused product.

Van Gogh’s bandwidth advantage really can’t be understated. Integrated GPUs often suffer from bandwidth limitations because they’re built into chips that emphasize CPU performance. Modern CPUs rely heavily on cache and generally don’t need lots of memory bandwidth to perform well, at least until you get to very high core counts and specialized applications. GPUs are another story because their working sets tend to be much larger, often making effective caching difficult. Worse, integrated GPUs have to fight with the CPU for memory bandwidth.

To counter this, the Steam Deck’s LPDDR5 setup provides compute-to-bandwidth ratios comparable to that of consoles. Massive memory bandwidth means there’s no need for an Infinity Cache. It further means the GPU should have plenty of bandwidth available even when it’s sharing a memory bus with the CPU. Finally, Van Gogh’s memory bandwidth strategy provides an interesting contrast to desktop GPUs, which are using larger caches instead of massive VRAM bandwidth. It looks like DRAM technology is still good enough to feed the bandwidth demands of small GPUs without incurring massive power costs.

If we lock desktop RDNA 2 to the same clocks, we see Van Gogh behaving very similarly right up to L2. There, Van Gogh’s smaller L2 is actually faster at matched clocks. Checking a smaller L2 is probably easier. A small GPU like the one on Van Gogh also has fewer L2 clients, further simplifying things and allowing for latency optimizations.

Past the L2, we can see desktop RDNA 2’s Infinity Cache. It’s prominently missing on Van Gogh. But again, Van Gogh relies on massive memory bandwidth rather than caches, so it doesn’t need an extra level of cache.
Compute Throughput
From a math throughput perspective, the Custom GPU 0405 is about the same size as Renoir’s iGPU. The throughput difference we see here comes down to the Ryzen 7 4800H only having seven Vega compute units enabled out of eight.

RDNA 2 therefore has its execution units balanced in a very similar way to Vega (and GCN). Less common operations like FP32 divide, remainder, reciprocal, and inverse square root execute at quarter rate. FP64 throughput is not prioritized in either product, though Vega can do FP64 adds at a slightly better 1:8 rate. FP64 multiply and multiply-add run at closer to 1:16 rate though, making those operations act like they do on RDNA 2.
Both architectures can get increased FP16 throughput by packing two FP16 values into a 32-bit register, and running packed operations on it. Usually that lets FP16 operations execute at double rate. Strangely that wasn’t achieved on Renoir for FMA operations. Neither architecture sees a substantial FP16 throughput advantage for special operations. Perhaps adding additional hardware for those operations wasn’t worth it.

Integer throughput tells a similar story. Again ratios for the common operations haven’t changed. If it worked well in GCN, there’s no need to mess around with it for RDNA. Integer addition executes at full rate, while less common operations like multiplies execute at quarter rate. Integer division and remainder operations get very low throughput.
Van Gogh does extend a notable lead for 64-bit vector integer operations. I’m not sure where that comes from because both architectures do vector 64-bit operations by handling each 32-bit half separately. For example, 64-bit addition would be performed by doing an add-with-carry (v_add_co_u32) on vector registers holding the low half of the 64-bit values. The vector condition code (VCC) would hold the carry flags, letting a subsequent v_add_co_ci_u32 (add with carry-in from VCC) produce a correct result for the upper half.
CPU to GPU Link Bandwidth
High LPDDR5 bandwidth has other uses too. DRAM acts as a backing store for transfers between the CPU and GPU. On an integrated GPU, more DRAM bandwidth means faster copies between CPU and GPU memory.

Van Gogh sees excellent transfer rates between the CPU and GPU. It’s a lot faster than Renoir, which is limited by DDR4 bandwidth. And, it’s faster than the RX 6900 XT, which is limited by PCIe 4.0. However, this impressive performance won’t be too important in a gaming platform. PCIe bandwidth doesn’t have a significant effect on gaming performance until you get to extremely slow configurations. It’s nice to have for compute applications that offload some work to the GPU, and then do some CPU-side processing on the results before the next iteration. But that’s not what Van Gogh is made for.
Final Words
AMD’s Van Gogh mates Zen 2 cores with a modern RDNA 2 architecture. On the surface, it might look like a compelling alternative to Renoir and Cezanne. Those mainstream laptop chips are stuck on AMD’s older Vega graphics architecture, which is a couple generations behind their desktop cards. But a closer look shows that Van Gogh is not a general purpose chip. Rather, Van tries to maximize GPU performance in a very tight power envelope, and makes heavy sacrifices to the CPU side.

Van Gogh only implements a single CCX, meaning that multithreaded performance will suffer compared Renoir’s two CCX configuration. Very slow clock ramp policies will impact responsiveness. The conservative 3.5 GHz max boost clock makes it one of the slowest client Zen 2 implementations. DRAM performance from the CPU side is disappointing, with high latency and poor bandwidth.
The Custom GPU 0405 looks better, but isn’t free of sacrifices. It doesn’t have the high clock speeds of desktop parts. It isn’t much larger than Renoir’s iGPU. It doesn’t have Infinity Cache. But it does get most of RDNA 2’s architectural advantages. And most importantly, Van Gogh has a ton of memory bandwidth on tap to feed that iGPU.
AMD’s Custom APU 0405 is therefore an interesting example of a very small console chip. Like its cousins in the PS5 and Xbox Series X, the CPU gets hobbled by low clock speeds, small caches, and high memory latency. But it is a showcase of how RDNA 2 can scale down to very low power targets while maintaining good performance. Even though CPU performance is weak relative to other Zen 2 implementations, Van Gogh’s CPU performance in isolation is quite credible. Zen 2 still brings in a big out-of-order engine with a host of advanced architectural features. It should be worlds ahead of the CPU found in Nintendo’s switch, which runs weaker Cortex A57 cores at even lower frequencies.

In that respect, it shows one of AMD’s primary advantages against giants like Nvidia and Intel. Nvidia has formidable graphics architectures, but doesn’t have a similarly strong CPU division. Intel is the other way around. AMD has both, letting it create strong APU implementations for products like the Steam Deck, Playstation 5, and Xbox Series X. In bad times, this strength kept AMD afloat until the company could bounce back. In better times, it makes AMD a strong competitor in niche markets, like the one the Steam Deck fills.
If you like our articles and journalism and you want to support us in our endeavors then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way or if you would like to talk with the Chips and Cheese staff and the people behind the scenes then consider joining our Discord.