
Knight’s Landing: Atom with AVX-512

Intel is known for their high performance cores, which combine large out of order execution engines with high clock speeds to maximize single threaded performance. But Intel also has the “Atom” line of architectures, which are designed to make different power, performance, and area tradeoffs. Alder Lake prominently featured the latest member of this “Atom” line; Gracemont helps improve performance per area, letting Intel stay competitive in multithreaded performance.
But that wasn’t the first time Intel deployed large numbers of Atom cores to improve throughput. Today, we’re looking at Xeon Phi, in Knight’s Landing form. Xeon Phi is a unique many-core CPU that aims to bridge the gap between GPUs and Intel’s more traditional CPUs. Knight’s Landing is the codename for the second generation Xeon Phi, which integrates 72 cores based on the Xeon Phi architecture. For a 2016 chip based on Intel’s 14 nm process, 72 cores is a lot. Today, Intel’s Ice Lake server chips only scale to 40 cores. Intel’s upcoming Sapphire Rapids CPUs are rumored to launch before the heat death of the universe, with just 60 cores.
Neither of those can match the core count of the Xeon Phi 7210 we tested. That SKU has 64 cores enabled. On top of that, each core has 4-way SMT, giving us access to 256 threads. Besides being one of the few Intel cores to support 4-way SMT, Knight’s Landing also integrates 16 GB of on-package MCDRAM. MCDRAM can be used alongside DDR4, acting either as cache or a separate pool of memory.
That makes Knight’s Landing quite a unique product. To be clear, Xeon Phi is not built to be a typical client or server CPU. It’s meant for high performance computing (HPC) applications, where it can bring massive vector throughput, high memory bandwidth, and the flexibility of a CPU.
Core Architecture
Knight’s Landing is based off the Silvermont architecture, but with huge modifications to support Xeon Phi’s HPC goals. Intel made the biggest modifications to the floating point (FP) and vector execution side, where Knight’s Landing gets AVX-512 support with 2×512-bit FMA capability. Full out-of-order execution is supported on the vector side, while Silvermont’s FPU executed operations in-order to save power. The backend has been massively scaled up as well, with reordering capacity more than doubled and other resources scaled up to match. Of course, the core also has SMT4 support, while Silvermont had no SMT capability.
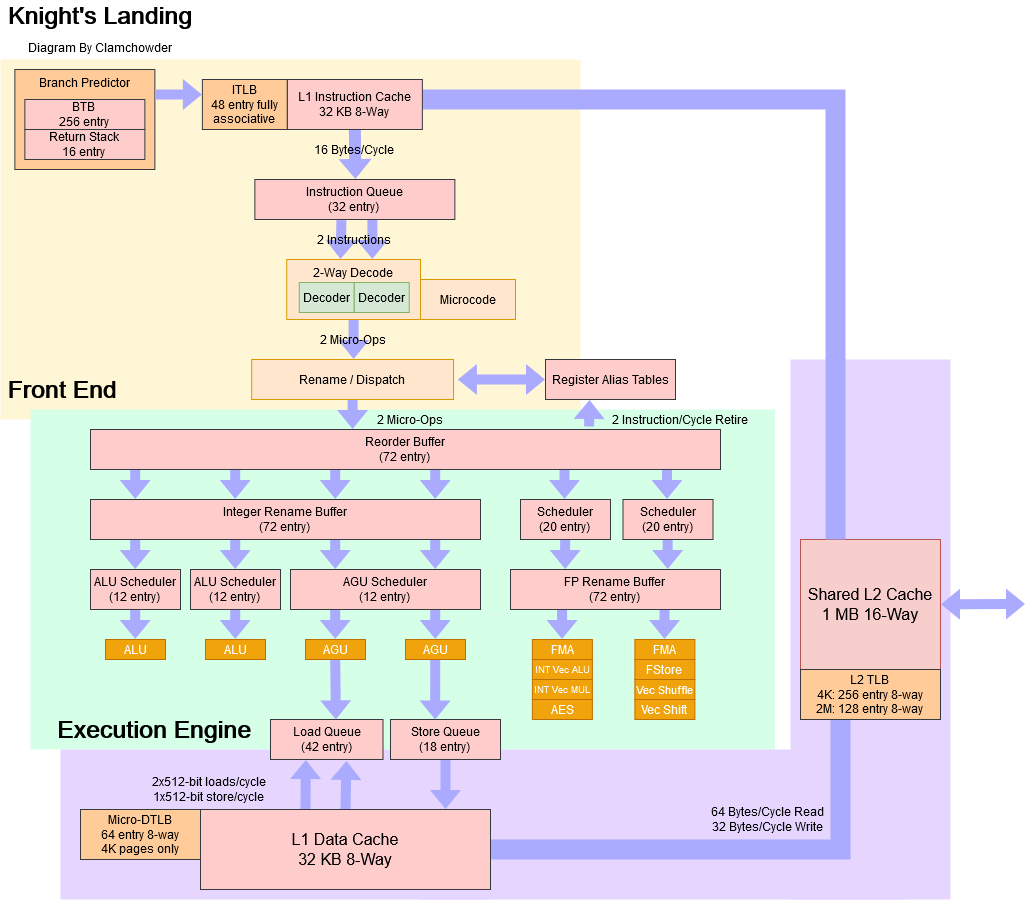
Other differences are more subtle. Knight’s Landing uses 46 physical address bits, while Silvermont only used 36. Silvermont could address 64 GB with those 36 address bits, which is more than adequate for low power client applications. But HPC applications need to deal with more memory than that. Alongside that, Intel also increased TLB and L1D capacity.
Frontend: Branch Prediction
A CPU’s branch predictor is responsible for quickly and accurately feeding the pipeline. Knight’s Landing has weak branch prediction capabilities and struggles to recognize long patterns.

This branch predictor is a step behind that of contemporary low power architectures like ARM’s Cortex A72. It’s not great, but such a design makes a tradeoff between power and performance that probably makes sense for HPC. The core doesn’t have particularly high reordering capacity, and HPC code typically doesn’t have a lot of branches to begin with. 4-way SMT also muddies the picture. On one hand, four threads will have a larger branch footprint than single thread, stretching the core’s already meager history tracking resources even thinner. On the other, a mispredict will only flush in-flight instructions for the thread that suffered it, potentially resulting in less wasted work.
KNL’s branch predictor is also light on branch target tracking capability. It can track up to 256 taken branches, and seems to be able to cover up to 4 KB of code. I guess that’s better than nothing, but it’s really nothing to be proud of either. Intel’s old P6 architecture had a 512 entry BTB.

KNL is also incapable of doing taken branches back to back. In branchy code, it could end up losing a lot of frontend throughput as the L1i fetch unit will idle for a cycle after any taken branch. In other words, the BTB has a minimum latency of two cycles. SMT can somewhat mitigate this, because the frontend can switch to another thread while waiting for the branch target to come from the BTB. BTB throughput is one taken branch target per cycle, and a Knight’s Landing core with at least two SMT threads active can achieve a throughput of one taken branch per cycle across all threads.
Compared to Cortex A72, Knight’s Landing has far lower branch target tracking capacity. ARM’s core has a second BTB level that can track more than 2048 branches, at the cost of taking another cycle. In exchange, the A72’s first level BTB is smaller, meaning that branchy code will quickly incur additional penalty cycles from hitting the second level BTB.

Neither architecture can do back to back taken branches for a single thread, but Cortex A72 can’t hide this flaw by running a second SMT thread in the core. For very large code footprints, Intel also has an advantage because the core seems to have fewer pipeline stages between L1i fetch and the branch address calculation logic in the decoders. If BTB capacity is exceeded, Knight’s Landing can resolve a taken branch target in seven cycles, while A72 takes 9-10 cycles.
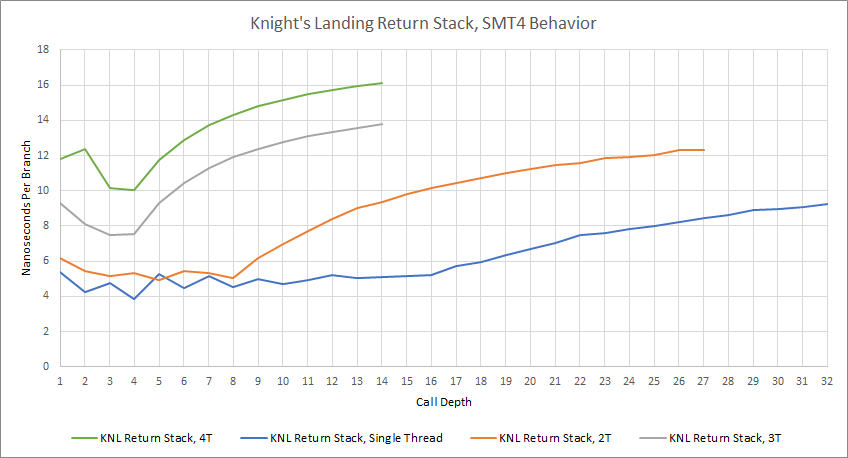
For return prediction, Knight’s Landing uses a 16 entry return stack. When multiple SMT threads are active, the return stack is statically partitioned. If only a single thread is busy, the core can give that thread all 16 entries. Two threads get eight entries each, and three or four threads each get four entries. The return stack can’t be partitioned into three parts, apparently, so loading three threads in a core will leave a portion of the return stack unused.
In Practice
Branch predictor performance is very application dependent, though running more SMT threads in a core will generally degrade prediction accuracy. In some cases, Knight’s Landing’s small predictor can perform reasonably well even when dealing with four threads.

If we focus on branch predictor performance for a single thread, Knight’s Landing does a better job than Phytium. That’s pretty impressive for a very small branch predictor, indicating that Intel did a good job of tuning how they used their prediction resources. However, it can’t match the larger predictors found in desktop architectures.

In other cases, the small branch predictor barely has enough resources to handle a single thread, and takes a massive drop in accuracy as more threads are loaded.
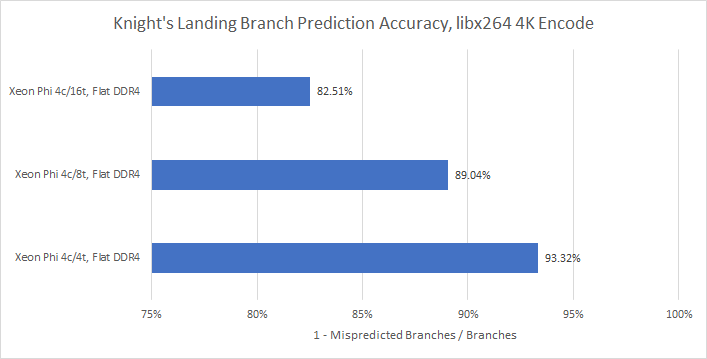
This is a pretty surprising result, because the high performance CPUs we’re used to testing usually have an easier time predicting branches in libx264 than 7-Zip. However, we do know that libx264’s instruction footprint is much larger than 7-Zip’s. We can also guess at how large the branch footprint is by looking at how often BAClears happen. In the Intel world, BAClears means that the frontend was resteered because the branch prediction unit couldn’t provide a correct prediction. To translate: there was a BTB miss, so the decoders had to calculate the branch target and do a small pipeline flush in the frontend.

With a single thread per core, we already see a pretty high BTB miss rate in both 7-Zip and libx264. As we load more SMT threads, the miss rate skyrockets for libx264. It increases for 7-Zip too, but the difference isn’t quite as drastic.
There aren’t too many SMT4 implementations out there, but we did briefly test IBM’s POWER9 on their cloud service. On paper, POWER9 cores are SMT8, but it’s probably more appropriate to call a single SMT8 core two SMT4 cores. POWER9 cores are much larger, and have far more substantial branch prediction resources than KNL cores.

As a result, IBM is able to run four threads in a core without crashing branch prediction accuracy. Knight’s Landing can’t do this. SMT4 actually still provides decent performance gains in this scenario, but branch prediction counters do show how a small branch predictor can struggle when given four threads. In the other direction, this result gives insight into why recent high performance cores have been investing so much into their branch predictors.
Frontend: Fetch and Decode
Like Silvermont, Knight’s Landing is a very small, 2-wide core. It’s fed by a 32 KB, 8-way instruction cache. This cache can generally provide enough bandwidth to feed the core. But it’s very important to make sure code fits within the L1i, because KNL is very slow when running code out of L2. This behavior is in line with other low power cores, like AMD’s Bobcat.
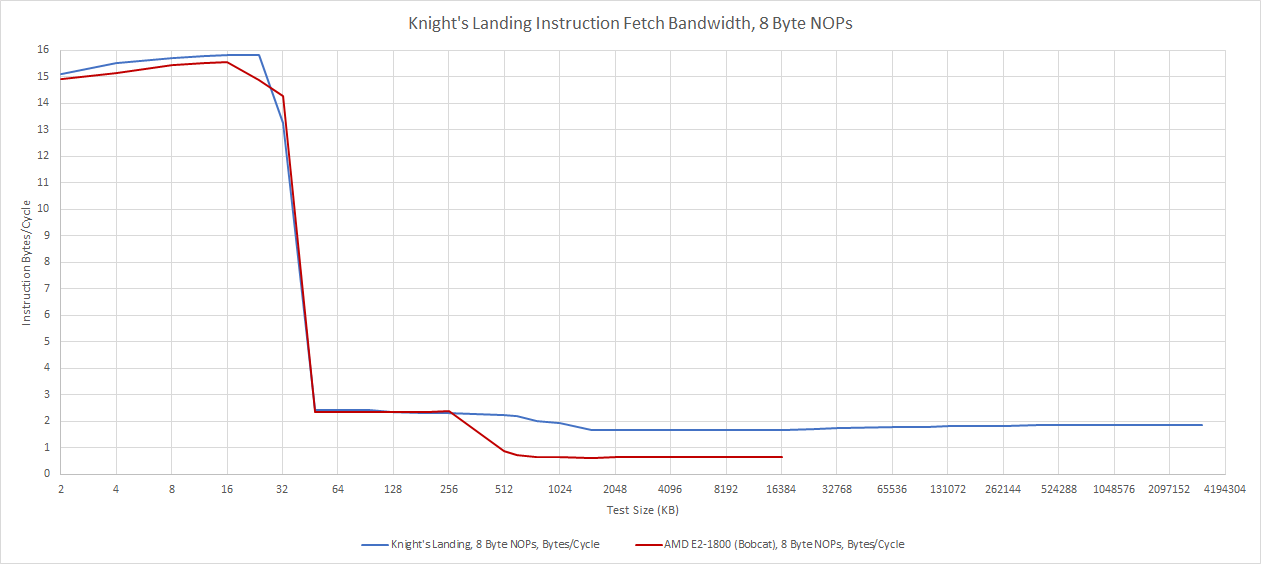
SMT does nothing to mitigate this: L2 code fetch bandwidth remains low even with all four SMT threads loaded, suggesting the bottleneck is low memory level parallelism from the instruction side. Code fetch throughput stays below 1 IPC even with smaller 4 byte instructions, which are more representative of scalar integer code.

In fairness to Knight’s Landing, AMD’s Bobcat suffers from similar problems. ARM’s Cortex A72 also can’t sustain 1 IPC when running code from L2. We only see reasonable throughput for large code sizes when we get to larger, higher performance cores. And for Xeon Phi’s HPC use case, instruction footprints would probably be small anyway.

However, this setup isn’t too well suited for running client applications. Client applications often have larger instruction footprints, and running multiple threads in a core will tend to mean less instruction-side locality. That reduces L1i caching effectiveness, and KNL’s low L2 code fetch bandwidth could be a significant opportunity for improvement.

Still, SMT helps the frontend feed the core better, even if instruction footprints are a bit too large. Multiple threads probably help hide BTB latency. If one thread stalls on a L1i miss, the frontend can fetch instructions for another thread, and hopefully find a L1i hit.
Rename/Allocate
Knight’s Landing has a very primitive renamer, and can’t even break dependencies when it sees common zeroing idioms. That means setting a register to zero is better done using a move immediate instruction, even if encoding that would take more space. Move elimination is also not supported.
Out of Order Execution Engine
Silvermont had a very small out of order execution engine. Knight’s Landing keeps the same backend layout, but significantly increases the size of most key structures. HPC code often needs to achieve high bandwidth, which means keeping a lot of requests in-flight to the memory subsystem in order to absorb latency. SMT4 also requires a larger backend to work well, because resources potentially have to be shared between four threads.
Like Silvermont, Knight’s Landing’s reorder buffer stores pointers to speculative register files, which Intel calls “rename buffers”. Architectural state is stored in a separate retired register file, and results are copied over at retirement. This setup behaves like P6-style ROB+RRF scheme, in that renaming capacity for the various register files can cover the entire ROB capacity.

In terms of resources available to a single thread, Knight’s Landing lands somewhere around AMD’s Athlon or Jaguar. But it’s quite incredible in that it has enough register renaming resources to cover the entire ROB size, including with mask registers and AVX-512 vector registers. For a single thread, this resource allocation is kind of overkill, because even in AVX-512 heavy code, not every instruction will write to a 512-bit vector register. You’re always going to have integer instructions for handling loop counts, branching, and memory addressing.
When more than one SMT thread is active, the core repartitions resources between threads. If two threads are active, each will get half of the available resources. Each thread will get a quarter if three or four threads are active. There’s no separate SMT partitioning mode if three threads are active. We can test this by running a structure size on one SMT thread, while a dummy load is run on other SMT threads in the same core.

Knight’s Landing’s resource allocation makes more sense for SMT4. In that mode, each thread only has a reordering capacity of 18 instructions. Making full use of that reordering capacity will be essential, so having register files cover all of that reordering capacity makes sense.
However, SMT4 mode does make load/store resources kind of tight. The store queue wasn’t too large to begin with, and cutting it in four means that each thread only has four entries available.

For comparison, Intel’s Pentium II and III have 12 store buffers, according to the optimization manual. Both CPUs have 40 entry reorder buffers, meaning no more than 30% of in-flight instructions can write to memory to hit maximum reordering capacity. For Knight’s Landing, that figure is 22%. While that ratio is a minor issue with one thread active, it’s more of an issue with four SMT threads because each thread is already very low on reordering capacity and has to make the most of it.
Integer Execution
Like Silvermont, Knight’s Landing has two ALU pipes, matching its pipeline width. Both pipes can handle common operations like integer additions and register to register MOVs. However, slightly less common operations like bitwise shifts and rotates can only execute down a single pipe. Integer multiplication performance is also low. 64-bit integer multiplies execute down one pipe at half rate, with a latency of 5 cycles.
The integer pipes are fed by two schedulers, each of which have 12 entries. That represents a 50% increase in integer scheduling capacity over Silvermont’s 8 entry schedulers. Like Intel’s P6 architecture, the integer scheduler holds inputs for instructions waiting to be fed to the execution units.
AVX-512 Execution
Intel spends nearly 40% of the core’s die area to implement wide AVX-512 execution, so Knight’s Landing gets some incredibly high throughput for a low power architecture. In fact, it almost feels like a small OoO core built around feeding giant vector units. Like Silvermont, Knight’s Landing doesn’t hold inputs in the vector scheduler. Doing so would make the scheduler structure way too large especially on KNL, where inputs can be 512 bits wide.

AVX-512 throughput is quite high. Per-cycle, Knight’s Landing can match Skylake-X’s FMA throughput. It can also do two 512-bit vector integer additions per cycle. However, latencies are generally high.

Even though the Xeon Phi 7210 only runs at 1.3 GHz, latencies are generally higher than on server Skylake. For example, a FMA operation takes 6 cycles to produce a result, but only takes four on Skylake-X. Vector integer operations also take two cycles, while they only take a single cycle on Skylake-X. However, long latencies tend to be common for low power designs. For example, Cortex A72 has 7 cycle FMA latency, and 3 cycles of latency for vector integer additions.
KNL’s vector register file also seems to be split into two parts, as the SRAM in the die shot doesn’t look uniform. I suspect it’s divided into a speculative register file with 72 entries (4.6 KB), and an architectural register file that can store non-speculative register state for all four threads (8 KB).
Memory Execution
Knight’s Landing has a 12 entry scheduler for memory operations, which is significantly larger than the 6 entry one on Silvermont. Like the integer scheduler, the memory scheduler holds inputs for operations waiting for execution. To calculate memory addresses, KNL has two AGUs, allowing it to sustain two memory operations per cycle. Both of these can be loads, and one of them can be a store. Silvermont only had a single AGU, for comparison.
Once memory addresses are calculated, the load/store unit has to ensure that memory accesses appear to happen in program order. If a store writes to a location that’s accessed by an in-flight load, that load needs to get its data from the store instead of pulling stale data from cache.
On Knight’s Landing, store to load forwarding works for exact address matches, with a latency of 6-7 cycles. Knight’s Landing seems to do memory dependency checks at 4 byte granularity. If a load and store access the same 4 byte aligned region, Knight’s Landing will use a slow 16 cycle path to complete the load, even if the two accesses don’t actually overlap. Intel’s big cores from Sandy Bridge to Skylake also do a check at 4 byte boundaries, but do a follow-up check and don’t incur such a heavy penalty if there’s no true overlap.
KNL’s load/store unit fails to do fast store forwarding if a load crosses a 64 byte cacheline boundary (i.e., is misaligned), with a cost of around 20 cycles.

Loads that cross a 64 byte cacheline boundary take two cycles to complete, while stores take four cycles if they cross a cacheline. Crossing a 4K page boundary is quite expensive on Knight’s Landing, regardless of whether a load or store is involved, and costs 14-15 cycles. Forwarding works similarly on the vector side, but with a latency of 9-10 cycles for a successfully forwarded store.
Cache and Memory Access
Knight’s Landing has a 32 KB L1 data cache, which is somewhat larger than the 24 KB one on Silvermont. Latency is 4 cycles, and the L1D is backed by a 1 MB L2 cache shared by the two cores on a mesh stop. L2 latency is fairly high at 17 cycles, but that’s about normal for a low power design. Cortex A72, as implemented in Amazon’s Graviton, has a larger L2 shared across 4 cores, with 21 cycles of latency.

Knight’s Landing has no on-die L3, meaning that each core has access to just 1 MB of on-die cache. Across the whole die, there’s 512 KB of cache per core. That’s better than a GPU, but the cache setup is still light compared to most high performance CPUs.
After a L2 miss, the memory request traverses the mesh to a tile that’s responsible for the requested cache line. Addresses are hashed to tiles much like in Skylake-X, but without the third level cache distributed across the mesh. Instead, there’s just a directory access to determine whether the data should be fetched form another tile, or from DRAM. DRAM access is also complicated, because Knight’s Landing supports both MCDRAM and traditional DDR4.

Much like HBM, MCDRAM is a form of on-package memory that takes advantage of short trace lengths and high wire density to provide very high memory bandwidth. Unlike HBM, MCDRAM doesn’t require an interposer and should be cheaper to utilize.
Knight’s Landing can directly address MCDRAM in “flat” mode, by mapping it into the upper part of the address space. Alternatively, MCDRAM can be set up as a direct-mapped cache with 64B lines. Direct-mapped means the cache is 1-way associative, so each memory location only maps to one location within the MCDRAM. Normally you don’t see a lot of direct mapped caches, but MCDRAM is special. It’s DRAM, which means it’s not particularly optimized for speed. That dictates the caching implementation.

Like HBM, MCDRAM is not optimized for latency. In flat mode on Knight’s Landing, MCDRAM latency is around 176 ns, while a DDR4 access has a latency of 147 ns. In quadrant mode with sub-NUMA clustering, which keeps directory checks within a quadrant and sends memory accesses to the nearest controller, MCDRAM latency improves to about 170 ns. The mesh interconnect therefore has a pretty minor impact on memory latency. Knight’s Landing does run the mesh faster than the core clock, which helps reduce time spent traversing the mesh. The Xeon Phi 7210 we tested runs the cores at 1.3 GHz, while the mesh runs at 1.6 GHz.

Using MCDRAM in cache mode adds 3-4 ns of latency over a plain MCDRAM access in flat mode. That corresponds to half a dozen cycles at mesh clock, which isn’t too bad for doing tag and status checks in the memory controller. On a MCDRAM cache miss, we see a painful >270 ns latency when hitting DDR4.
KNL’s TLB setup doesn’t help things either, and we run into page walk latency even if we use 2 MB pages. The L2 TLB only has 128 entries for 2 MB pages, meaning that random accesses over more than 256 MB will cause misses. KNL also shows its Silvermont origins with a 64 entry first-level TLB (uTLB) that only supports 4 KB pages. Even though we used 2 MB pages, those get chopped up into 4 KB chunks in the first level TLB, resulting in higher latency after 256 KB. A uTLB miss that’s satisfied from the L2 TLB adds another 6 cycles of latency, while a L2 TLB miss adds over 20 cycles.

TLB miss latency can significantly increase memory latency for applications that use 4 KB pages. Most client applications do use 4 KB pages, but Knight’s Landing doesn’t target client users. Latency is less of a priority than throughput, and that’s really where MCDRAM comes into play.
Bandwidth
Silvermont had unimpressive L1D bandwidth, because that wasn’t a priority in a low power client design with mediocre vector throughput. Knight’s Landing on the other hand is a vector performance monster, and has L1D bandwidth to match. The L1D can handle two operations per cycle. Both can be loads, and up to one of them can be a store. We didn’t quite get there with our read memory bandwidth test, but our instruction rate test did show the core sustaining 2×512-bit loads per cycle. And we did get over 64 bytes per cycle with a 1:1 read to write ratio, by adding a constant to every element in an array.

The L2 cache can deliver up to 64 bytes per cycle, though we got slightly lower than that from a single core. Both cores together can pull pretty close to 64 bytes per cycle from L2. From DRAM, we get around 13 GB/s from a single core if we load all the SMT threads. Bandwidth from DRAM doesn’t increase much if we use both cores on a mesh tile.
If we load all threads and look at DRAM-sized regions, the fun really starts. MCDRAM does exactly what it was designed to do, and provides a massive amount of bandwidth.
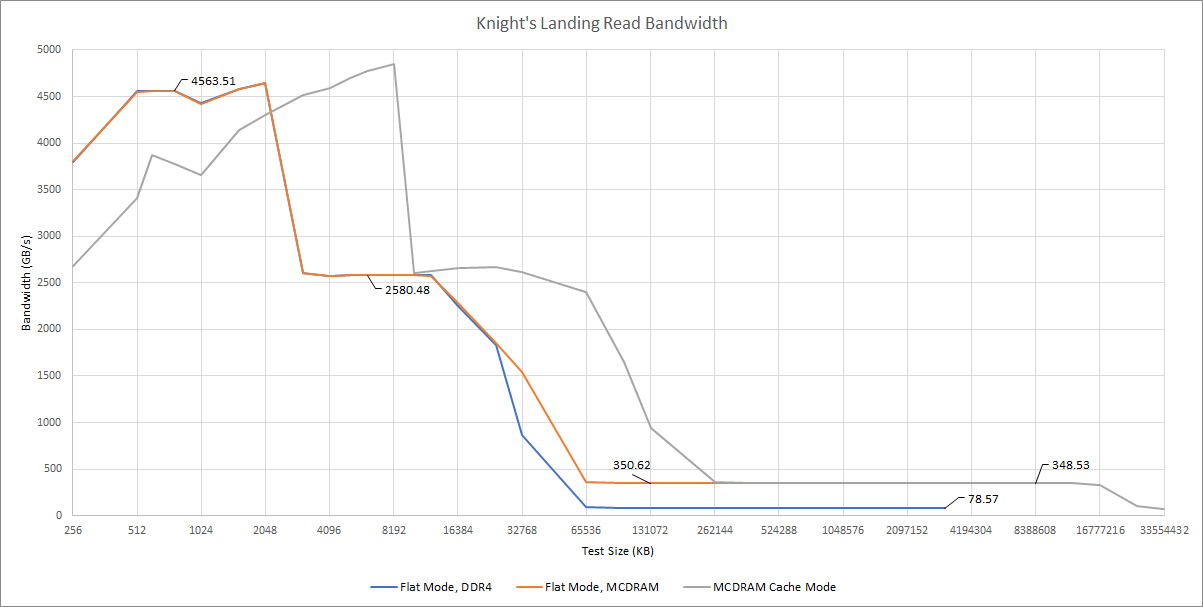
We also see very little bandwidth penalty from using cache mode. All of this is an impressive performance considering Knight’s Landing has 16 GB of MCDRAM capacity.
Dmidecode reports eight 6400 MT/s MCDRAM devices, each with 2 GB of capacity, 64 bits of data width (or 72 bits if ECC is included). If we use that in a bandwidth calculation, we should get 409.6 GB/s of theoretical bandwidth. The read bandwidth test achieved a pretty reasonable 85.6% efficiency, if that’s the case.
In any case, 350 GB/s is higher than the theoretical bandwidth of the contemporary GTX 980 Ti’s 384-bit GDDR5 setup. At the same time, MCDRAM offers 16 GB of capacity, which makes for an impressive combo. We also can’t forget that Knight’s Landing enjoys over 78 GB/s of bandwidth to a 96 GB pool of DDR4. If a GPU had to deal with that much memory, it’d have to move data over a relatively slow PCIe bus. Even a PCIe Gen 4 x16 link can’t provide that much bandwidth.
Quadrant Mode, and Hybrid Mode
In addition to the flat and cache modes, Knight’s Landing can also operate the MCDRAM in a hybrid configuration. In hybrid mode, half of the MCDRAM is accessible as in flat mode, while the other half acts as cache. We tested hybrid mode with a quadrant mode, SNC4 setup. That further divides the memory subsystem into four quadrants, with each NUMA node accessing the memory controllers closest to it. Hybrid mode’s caching capacity is similarly split up, exposing eight NUMA nodes. Nodes 0 to 3 correspond to the CPU cores on each quadrant, and DDR4 with 2 GB of MCDRAM caching. Nodes 4 to 7 point to the local MCDRAM channels on each quadrant, each with 2 GB of capacity (the other 2 GB would be used as cache). Unsurprisingly, we see MCDRAM-as-cache bandwidth drop off sooner than it does in pure cache mode with no partitioning.

But there are some surprises as well. From a single NUMA node, we actually get slightly higher bandwidth from MCDRAM getting used as cache than from directly addressed MCDRAM. Multiplying that by 4 gives us higher total bandwidth (512 MB test size, 88.98 GB/s * 4 = 355.92 GB/s) than the 350 GB/s we get from hitting all the MCDRAM channels in flat mode. But I’m surprised at how small that difference is. There’s not a lot of gain by partitioning the chip into four quadrants, suggesting the mesh interconnect can support a lot of bandwidth. With latency, we see a similar picture. Hitting the local MCDRAM controller drops latency from about 179 ns to 170 ns. It’s an improvement for sure, but latency is still much higher than DDR4 latency, and suggests that MCDRAM is simply optimized for high bandwidth rather than low latency.

Placing KNL into flat mode with a quadrant+SNC4 setup shows that DDR4 latency can get down to 143 ns. Again, hitting the closest memory controller saves a bit of memory access time, but doesn’t make a large difference.
From another perspective, Knight’s Landing has very pleasant NUMA characteristics when running in SNC4 mode. A single node can pull almost as much bandwidth off a remote node’s memory as it can with local memory. Latency penalties are light as well. KNL is a monolithic chip after all with a lot of mesh links between each NUMA node, so that’s not surprising.
Bandwidth Scaling
Most CPUs can reach maximum DRAM bandwidth with just a few cores active. But Knight’s Landing has a unique combination of weak cores and tons of DRAM bandwidth. So, we basically need all of the cores loaded in order to max out MCDRAM bandwidth. To saturate DDR4 bandwidth, we need about 10 cores loaded.

Core to Core Latency
This test measures contested lock latency. Knight’s Landing uses dual core clusters, with each cluster placed on a mesh stop. Coherency is maintained with a directory distributed across the mesh.

Latencies are generally high, thanks to low mesh and core clocks. We see about 41 ns for between cores within the same tile, and 23 ns for threads running within the same core. Going across tiles costs between 80 and 100 ns, depending on how far away the you are from the tile that the cache line is homed to.
In quadrant mode with sub-NUMA clustering (SNC4), the mesh is split into four quadrants. Directory lookups become local to a quadrant, but that doesn’t really change core to core latency behavior.

In terms of memory bandwidth and latency, quadrant mode has a measurable but small impact. MCDRAM Bandwidth across NUMA nodes is only slightly lower (~86 GB/s vs ~90 GB/s), while DDR4 bandwidth is almost identical (19.1 GB/s vs 20.8 GB/s). NUMA-aware applications that can take advantage of quadrant and SNC4 mode will see slight performance benefits, but non-NUMA aware programs aren’t held back much.
SMT Scaling
Usually, we see SMT implemented on high performance cores to increase area efficiency. Going for maximum single threaded performance often involves pushing structure sizes to the point of diminishing returns. Partitioning those resources between two or more threads makes sense, because diminishing returns will apply less to each thread. For example, two threads can each make better use of a 96 entry ROB, than one thread can make use of a 192 entry one.
In contrast, Knight’s Landing is a very small core. Implementing SMT, let alone 4-way SMT, might seem like a strange move. However, KNL is designed to make sure it can make the best use of its reordering capacity. Unlike a lot of larger cores, KNL has large enough register files to cover all of its ROB capacity. The core also doesn’t have separate reordering limits for branches. All of that means KNL’s 72 entry ROB goes further than you might expect. The same applies when the ROB is split across four threads.
Knight’s Landing also suffers from latency issues. FP execution latency is high. Taken branches can’t execute back to back from a single thread. L2 latency is 17 cycles, and there’s no on-die L3 behind it. SMT can help fill gaps caused by dependency chains within a single thread. All of these factors together mean that Knight’s Landing actually enjoys significant performance improvements from 4-way SMT, provided there aren’t any bandwidth bottlenecks in play.

If we look at performance relative to running a single thread in each core, we see plenty of gain from SMT:

Of course, SMT can’t help you if you’re memory bandwidth bound. Running a client application across a few cores probably won’t do it, but a very throughput bound application will. If memory bandwidth is a bottleneck, SMT can actually make things worse by thrashing the on-die caches. We can already see that happen if we look at offcore responses per instruction. These are offcore responses either from DDR4 or MCDRAM, and correspond to memory accesses that couldn’t be serviced from the on-tile caches.
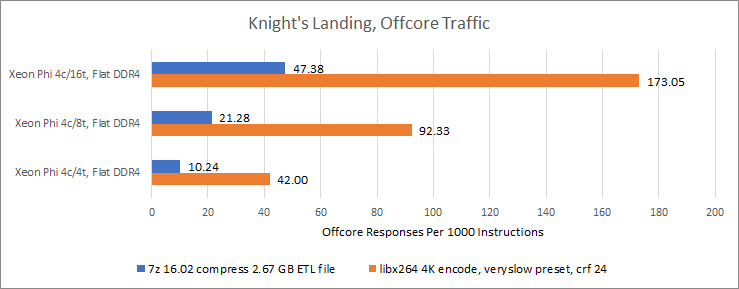
Now, let’s look at Y-Cruncher, a well vectorized application that tends to use a lot of memory bandwidth. With DDR4, we get negative scaling by running more threads than there are physical cores. Thrashing the caches with more threads only exacerbates the DDR4 bandwidth bottleneck.

But Y-Cruncher is also where Knight’s Landing shows off its strength. Y-Cruncher shines with MCDRAM, letting Knight’s Landing beat some modern desktop chips. With all 256 threads loaded, it beats the Zen 2 based Ryzen 3950X by a wide margin. The 3950X in this case is so memory bandwidth bottlenecked that performance did not increase when boost was enabled. Increased frequencies from boost were simply offset by decreases in IPC. MCDRAM didn’t make a difference for libx264 and 7-Zip. In fact, running 7-Zip off MCDRAM slightly reduced performance, probably due to higher latency.
Physical Implementation
Knight’s Landing is implemented on a large, 656 mm2 die. A lot of small cores mean a lot of die area is spent on cache and mesh interfaces. Within each tile, about 3.58 mm2 is spent on implementing a mesh stop and shared L2. KNL also spends a lot of die area on buses to carry data around the chip.

Each core occupies about 2.93 mm2, making it significantly smaller than a Skylake core implemented on the same 14nm process. Within a KNL core, the vector execution unit occupies about 1.14 mm2, or 39% of core area. The L1 data cache seems to sacrifice density for throughput, and takes just over 10% of core area.
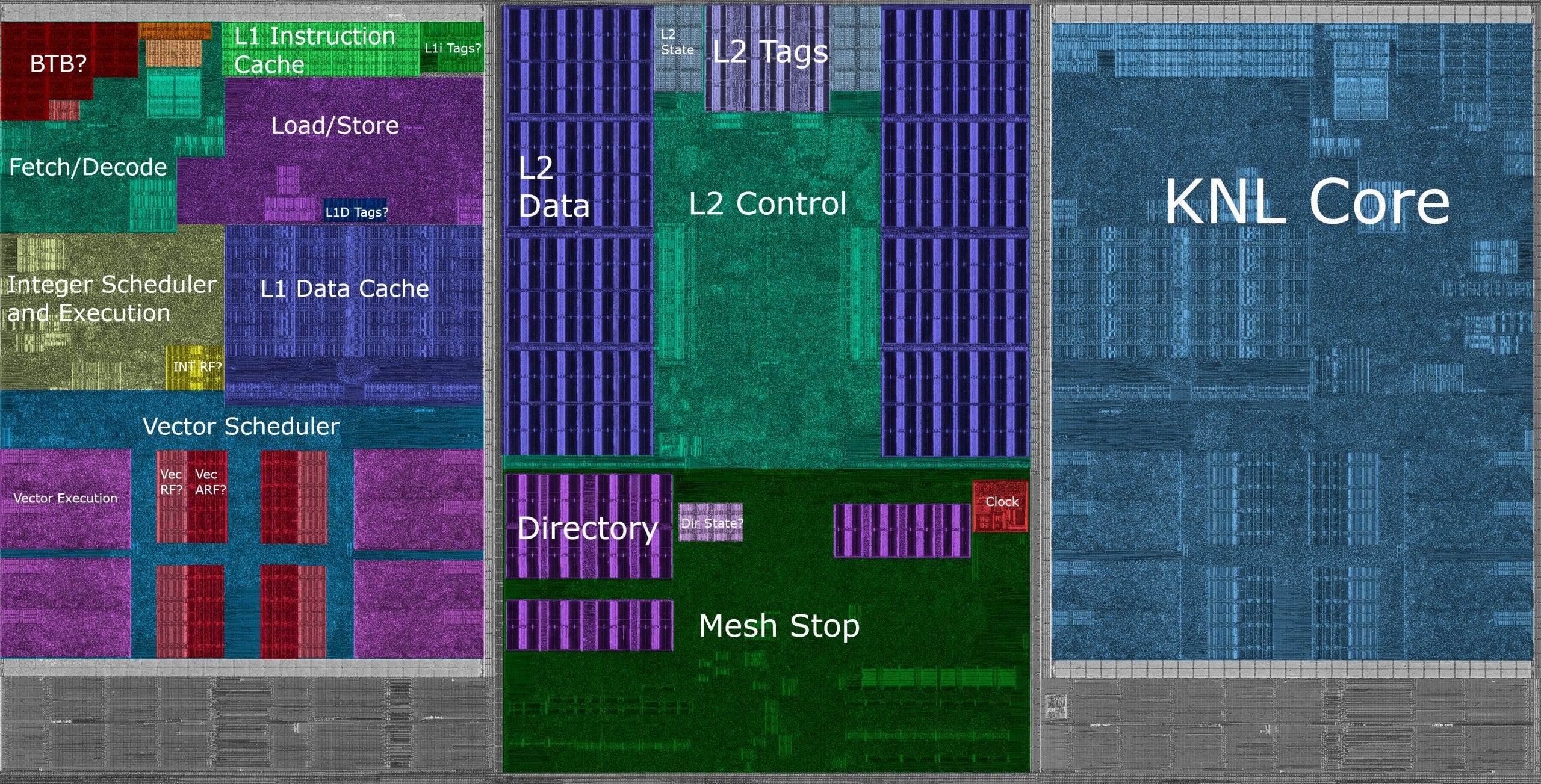
Compared to Silvermont, Knight’s Landing cores look completely different, showing that Intel can make drastic modifications to an architecture to make it fill a different role. The die shots also show that core layout can’t really be used as a proxy for architectural similarity. Knight’s Landing is mostly a scaled up Silvermont, but has a very different floorplan. Meanwhile, Sandy Bridge has a completely reworked architecture compared to Nehalem, with very few similarities to be found anywhere in the pipeline. But both have a similar floorplan.

Each Silvermont dual core module seems to spend less area on L2 control and offcore interface logic, probably because Silvermont doesn’t need deep queues to achieve high bandwidth to high latency MCDRAM. Outside the modules, Silvermont cores are connected via a Nehalem-like crossbar, in contrast to the mesh on Knight’s Landing. This crossbar isn’t as scalable and only supports 25.6 GB/s of memory traffic, while the KNL mesh can handle over 300 GB/s from MCDRAM.
Clock Ramp Behavior
The Xeon Phi 7210 idles at around 1 GHz, which means it’s never too far away from its typical 1.3 GHz clock speed. According to Intel’s slides, the Xeon Phi 7210 is capable of boosting to 1.5 GHz with a single tile active, or 1.4 GHz with all tiles active. However, we didn’t observe any clock speeds higher than 1.3 GHz. Turbo boost may have been disabled in the board’s firmware.
The chip takes almost 90 ms to reach 1.3 GHz, making it somewhat slower at increasing clock speeds than desktop CPUs that rely on OS controlled P-States. Clocks increase in 100 MHz steps after 80 ms.

Boosting behavior is unlikely to be a big deal for Xeon Phi, because it’s not meant to handle client workloads where responsiveness matters. And unlike desktop CPUs, Xeon Phi’s idle clock is not far off its maximum frequency.
Final Words
Knight’s Landing is an interesting product. Its lineage goes back to Intel’s Larrabee project, which used heavily modified P54C cores in an attempt to build a GPU. P54C is the original Pentium architecture, which is 2-wide, in-order architecture from the early 1990s. At this stage, Intel actually considered using their first-generation Atom architecture, Bonnell, but that was too risky because Bonnell was still under development.
So, Larrabee implemented P54C cores with 512-bit vector units. Performance issues from in-order execution were mitigated with 4-way SMT. Larrabee evolved into Knight’s Ferry, which implemented 32 of those cores with a ring bus interconnect and GDDR3 memory. Even though Knight’s Ferry already aimed for HPC rather than GPU use cases, it could still drive a display, and had texture units. Knight’s Corner moved to 22 nm, implemented 62 cores, and dropped display output capability to focus harder on HPC. In 2016, Knight’s Landing landed with 76 cores, implemented on Intel’s 14 nm process. Texture units disappeared, and Knight’s Landing switched to a mesh interconnect to support the higher core count.
The cores themselves switched off their P54C base in favor of a modified Silvermont architecture. Compared to P54C, Silvermont was far more modern and had out of order execution capability. That improves thread-limited performance, which was a weakness in earlier Xeon Phi architectures. Unlike Haswell and Sandy Bridge, Knight’s Landing still focuses on throughput rather than single threaded performance. That’s because Xeon Phi still doesn’t target the server and desktop markets. Instead, it offers a middle ground between server CPUs and GPUs. Like a GPU, Knight’s Landing has tremendous vector throughput, lots of processing units, and a ton of memory bandwidth.
But unlike a GPU, KNL is still built on top of CPU cores, and is far more programmer friendly. Execution and memory access latencies are lower than that of GPUs, allowing better performance when limited parallelism is available. Knight’s Landing’s branch predictor is basic, but it’s much better than stalling until a branch target is resolved, and then paying divergence costs. A small out-of-order execution engine is much better than stalling every time an instruction tries to consume the result of a cache miss. Programmers also get comforts like high speed access to a very large pool of DDR4 alongside a smaller pool of high bandwidth MCDRAM. Compare that to a GPU, which has to access host system memory via a slow PCIe bus.
Knight’s Landing went on to see service in the Stampede2 supercomputer, as well as a batch of others. As a result, there’s plenty of research out there on its HPC performance characteristics. But Knight’s Landing is fascinating from a non-HPC perspective as well, because it makes a lot of unique design tradeoffs to emphasize high multithreaded performance. The 4-way SMT implementation provides surprisingly good performance gains. Y-Cruncher shows that KNL’s high core count, 4-way SMT, and massive MCDRAM bandwidth can let it outperform modern desktop chips, even though each KNL core is individually very weak. At the same time, other applications simply can’t scale to fill 256 threads, showing the limits of spamming weak cores. Newer products like AMD’s Bergamo also offer 256 threads in a socket, but provide much higher single threaded performance. It’ll be interesting to see how those do going forward.
If you like our articles and journalism and you want to support us in our endeavors then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way or if you would like to talk with the Chips and Cheese staff and the people behind the scenes then consider joining our Discord.
I have a Knights Mill (7285) workstation if you would like to run tests on it for comparison with Knights Landing. Just ping me. I love your articles and would find it fascinating.
Have you done any tests with a dual socket xeon phi x200 cpu. I've been struggling to find a compatible motherboard for almost a year now. Also were the Xeon Phi x200 cpu's considered intel first generation scalable cpu's or second generation. Thanks for your time and have a happy new years!