
Why you can’t trust CPUID


While AMD is most certainly planning more processors based on the Zen 4 architecture, unfortunately many of the “leaked” Geekbench 5 results that made the rounds on social media yesterday are faked. However, that doesn’t mean they deserve flak for their reporting, because at the end of the day these fake results are indistinguishable from real results. We will explain how we did this later, but first we need to discuss how trivial it is to forge realistic test results.
All of these test results are made possible through the editing of a set of six CPUID MSRs that hold the processor name string, that are both readable and writeable according to AMD’s Processor Programming Reference (PPR) sheets. We have provided a section from AMD’s PPR for Zen3 to provide more information on how these MSRs work. You can find that below.

From our testing, these are writeable even as far back as Bulldozer; however, the ability of software to detect the changes is inconsistent. These MSRs are normally written at boot to set the processor name, and then read through the CPUID instruction when needed, such as during Geekbench 5 system information collection.
With 6 registers having 8 characters each, there are a total of 48 characters possible; however, the CPU name returned by the CPUID instruction has to be null terminated. This allows us to set a name with up to 47 characters, which is conveniently the perfect size for a Prequel meme.
Jokes aside, the ability to edit this after boot has severe consequences, as previously mentioned. So let’s go over a few applications and how they are impacted, starting with CPU-Z.
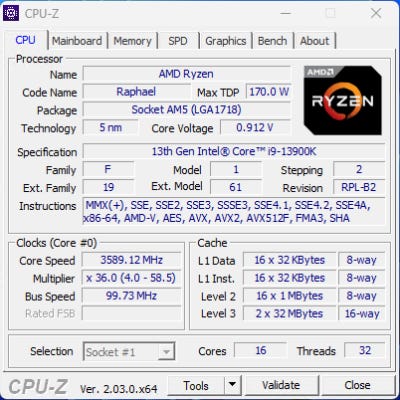
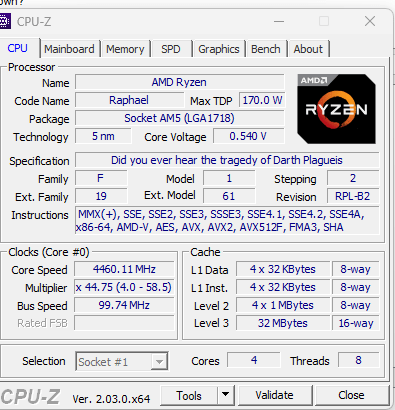
As you can clearly see, CPU-Z still knows it’s an AMD processor with the Zen 4 architecture, but the CPUID is completely wrong. That’s because CPU-Z uses the CPUID instruction to get the processor brand string. This is done by setting the EAX register to 0x80000002, calling CPUID, and getting the first 16 characters back in registers EAX, EBX, ECX, and EDX. The process is repeated with EAX set to 0x80000003 and 0x80000004 to get two more sets of 16 characters, giving a 48 character string. We can control what AMD’s Zen CPUs return in response to that sequence of CPUID calls, which means any tool relying on that CPUID feature will report whatever name we like. But to the untrained eye it looks realistic. CPU-Z is just one example of an application that is affected.
Now let’s move onto the results that went viral, the Geekbench 5 results.

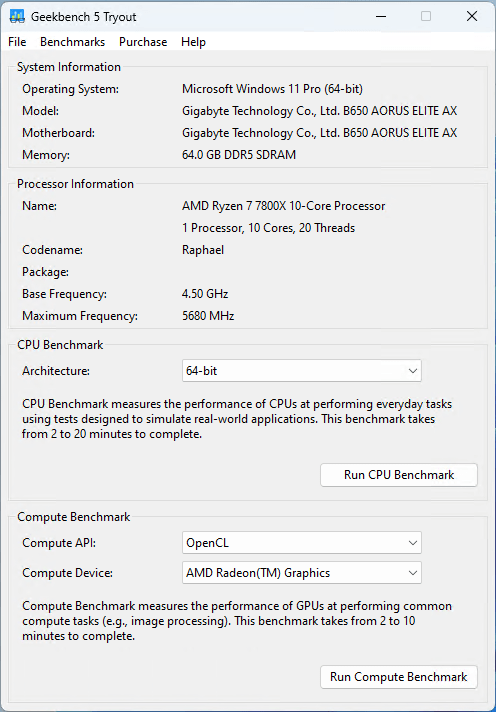
This is where the majority of the problems are with most benchmarking software: you can’t tell that it is fake, as the performance is right where the hypothetical processor should be and there’s nothing to suggest the CPUID was changed. It is using the same instructions as CPU-Z is, therefore it is vulnerable for the same reasons.
We have tested Geekbench, Cinebench, AIDA64, HWMonitor, Blender Benchmark, and many more. All of them are impacted and show the modified CPUID.
Of course this leads to an important question: what applications can we trust? The answer is just about nothing. If we know our application is running on bare metal, we can trust certain parameters returned by the CPUID instruction.
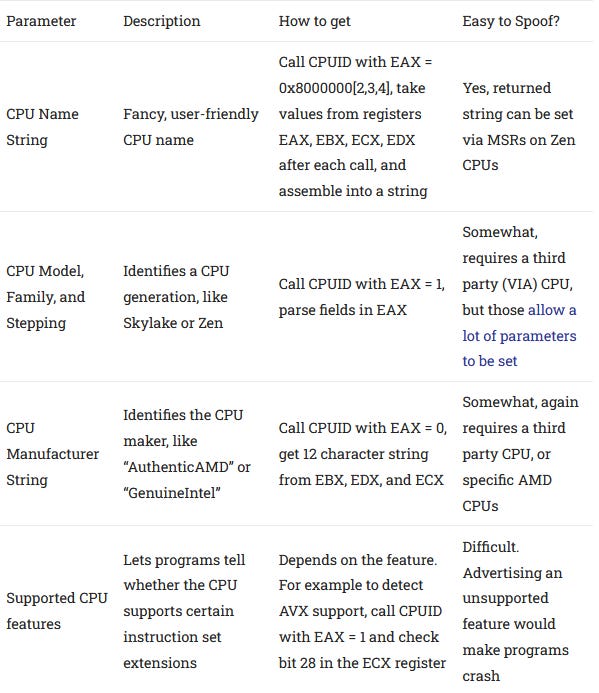
As you can see, identifying a CPU via the standard CPUID instruction can be fraught with peril. With bare metal access, you can at least identify the CPU generation with some level of confidence, unless someone gets their hands on a less common CPU. But everything goes out the window once virtualization is involved. A hypervisor can intercept the CPUID instruction and report whatever it likes, regardless of the underlying hardware.
Fortunately there are a couple pieces of software that don’t utilize the CPUID instruction. Two examples being HWiNFO & BenchMate (which utilizes HWiNFO) as they seemingly communicate with nonstandard, vendor specific components to acquire information about the processor. For example, the SMU can be queried on newer AMD CPUs.
But to be safe, it’s best to shy away from reporting rumors. The manufacturer is the best source of info for what processor SKUs will hit the market, unless perhaps they decide to unlaunch a SKU after the fact.
Now for those who still want to fool their friends, here’s a quick explanation on how we made the AMD Ryzen 7 7800X. First, get some capable hardware that has more resources than the SKU you are trying to make; an AMD Ryzen 9 7950X and an overclocking-ready board will cover this. Then you’ll need some software to change the CPUID. This is covered by an application called PMCReader that was created by clamchowder, one of our own authors. It was originally made to figure out CPU bottlenecks, but it is now being utilized to set the CPUID MSRs to see what is possible. Now, once you add in a negative 350mhz PBO offset and remove 3 cores per CCD, you have a compelling and realistic looking system that’ll fool most people. While it won’t work for every piece of software, and sometimes it just won’t work at all on certain machines, it clearly works well enough to make the rounds on social media.
If you like our articles and journalism and you want to support us in our endeavors then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way or if you would like to talk with the Chips and Cheese staff and the people behind the scenes then consider joining our Discord.