
Tachyum: Too Good to be True?


Author’s Note: Since the publication of this article, we have since had an interview with Tachyum and nearly all of the architectural analysis done in this article is outdated but it will be kept up for posterity. So please visit the new article for our revised analysis (https://chipsandcheese.substack.com/p/tachyums-revised-prodigy-architecture).
Tachyum is a name that’s been popping up in news articles everywhere, talking about how they are going to be everything from a general-purpose CPU faster than AMD’s 64-core Milan, to a SIMD accelerator on par with Intel’s Ponte Vecchio. And, they can do AI operations faster than NVIDIA’s H100 – all in a single chip!
There is an old saying some of y’all reading this article will know, “If it is too good to be true, it probably is,” which feels like the case with Tachyum. They are claiming to be able to do all these wonderful things with little to no downsides and I just don’t see how it is possible. So let’s start with the story, so far, of Tachyum.
The Story
Tachyum launched on February 8, 2017, with plans to have their brand new CPU expected to be in production products by late 2020 according to a Microprocessor Report published in October of 2018. This is an insane turnaround time given what Tachyum wanted to do. Even the big high-performance semiconductor companies don’t have schedules this aggressive and they have been doing chip design for decades with a lot more funding than Tachyum has.
At Hot Chips 30 (2018) Tachyum revealed the architecture that they were developing and started to set off alarm bells because Tachyum were comparing their Prodigy architecture to Intel’s failed Itanium architecture.
For those who don’t know, Itanium was Intel’s first commercial 64-bit ISA and architecture family and it was a very large departure from x86. Itanium, also called IA-64, was not an out-of-order superscalar CPU like x86 was. It was instead a VLIW (Very Long Instruction Word) CPU which was an in-order design that relies on the compiler to decide what instructions to execute to get the most out of the architecture. This means that Itanium was very reliant on the compiler which ended up being a large reason for the downfall of Itanium in the high-performance market and this is a problem that Tachyum will also encounter.
However, there is an area of computing where VLIW architectures have taken off and that is in Digital Signal Processors. DSPs are used in a variety of tasks such as image processing, audio recreation, radios, etc. However, a place you do not see DSPs is in high-performance computing because while they are very good at certain tasks, they are fairly specialized so they perform general-purpose tasks quite poorly.
Circling back to Tachyum, back in 2018 they said that they would be shipping production systems by the end of 2020. However, in October 2020, Tachyum announced that they were delaying Prodigy to a 2021 release but that they would be in volume production by the end of 2021. Then June 1st 2021 came and Tachyum announced that they had transitioned to TSMC’s N5 process for the Prodigy Universal Processor. While this move to N5 allowed Tachyum to expand its Universal Processor in terms of scope and ability, it set Tachyum’s timeline back to 2022. It is now 2022 and Tachyum has yet to ship any production systems with the closest that Tachyum has come to shipping production silicon being an FPGA emulation system. Tachyum claims that they will have systems sampling in Q4 of this year, which means that the earliest that Tachyum will be able to have general availability of their systems is the middle of 2023.
And now, it is time to take a look at the Prodigy architecture and see what it brings to the table.
The Prodigy Architecture
Now, this section has to come with a massive disclaimer: We can only assess what Tachyum has said about their Prodigy architecture which has changed from 2018 to 2022. So, as a result, we are going to cover what hasn’t changed between 2018 Prodigy and 2022 Prodigy first, then look at what has changed between the two.
What is most likely the same?
The Branch Predictor
Tachyum hasn’t said that their branch predictor has changed between the 2018 Prodigy and the 2022 Prodigy so we are going to assume that the 2022 Branch Predictor is the same as the 2018 Branch Predictor.
With this assumption, Prodigy uses a “skewed-Gshare-like” direction predictor with 12 bits of global history. Gshare uses global history to index into a shared array of saturating counters, often by XOR-ing the history buffer with the branch address. This prediction technique was very popular in the early to mid-2000s. Examples include Intel’s Pentium 4, which used a Gshare predictor with 16 bits of global history. And AMD’s Athlon 64, which employed a Gshare predictor with 8 bits of global history. Prodigy may achieve slightly better accuracy if it uses a larger history table or better hashing to prevent destructive interference. But Prodigy’s prediction algorithm has not been state-of-the-art in high-performance CPUs for the past decade.

If we look closer at the last decade, Prodigy’s predictor clearly falls behind. AMD’s Bulldozer uses both local and global history with a meta predictor that picks the best-performing scheme. From our tests, such a setup outperforms global or local history alone, unless Gshare is given insanely huge storage budgets. Prodigy’s predictor looks ancient next to recent Intel and AMD CPUs, which sport TAGE and perceptron predictors. Those state-of-the-art predictors offer even better accuracy with the same storage budget.
In Prodigy’s favor, its branch mispredict penalty is relatively short at just 7 cycles. That’s better than even slow-clocked CPUs like Neoverse N1, which has 9-11 pipeline stages before a mispredict can be detected. Higher clocked CPUs like AMD’s Zen 3 have a typical mispredict penalty of 13 cycles, according to AMD’s optimization manual. Also, Zen 3 and Neoverse N1 use out-of-order execution to achieve high performance per clock. They can have hundreds of instructions in flight, making a mispredict very costly in terms of wasted work.
Similarly, Prodigy’s branch target tracking is also dated. Tracking 1024 branch targets is probably fine if you’re living in the early 2000s. It’s not fine when you compare it against anything from the past decade, or even a bit before. Consider, for example, that AMD’s Athlon 64 can track 2048 branch targets along with Intel’s Netburst being able to track up to 4096 branch targets. And now compare that to some newer architectures:

Prodigy’s speed around taken branches is also unimpressive. It’s only able to track 16 branches with no frontend pipeline stalls after them. Contemporary high-performance CPUs can track a lot more branches in every speed band.
But it gets worse. According to MPR, each L1i cache line has fields for two branch targets. That means branch targets pretty much come for free with an L1i fetch. There’s no need to index into a separate branch target buffer. But this technique is dated too. Modern CPUs decoupled the BTB to enable accurate prefetching after an L1i miss. The branch predictor keeps generating fetch targets as long as it gets BTB hits and queues those up for the instruction fetch unit. That naturally gives very accurate instruction prefetch, enabling high instruction throughput even when instructions have to be pulled from L2 and beyond (provided that the branch predictor is accurate and the BTB is large enough). Prodigy can’t do this, meaning that instruction cache misses will carry higher penalties than they would in Intel and AMD’s chips.
However there is a silver lining of sorts here, due to both 2018 Prodigy and 2022 Prodigy being VLIW architectures where the compiler should be able to hint to the CPU when a branch is taken or not taken, a cutting edge branch predictor is not as critical as architectures such as Zen 3 or Golden Cove along with 2022 Prodigy possibly having increased the BTB capacity due to a much larger L1i.
Frontend and ISA
Now this one is a little contentious because on the Prodigy Spec Sheet it says that it is a 4 wide out-of-order core, however in this interview by golem.de the CEO of Tachyum, Radoslav Danilak, says that Tachyum developed an ISA and architecture based on VLIW principles. So how can we unify these two seemingly conflicting pieces of information?
Tachyum’s slides from Hot Chips 2018 say Prodigy can sustain “up to 8 RISC-style micro-ops/cycle.” and Microprocessor Report’s piece calls Prodigy a “four bundle eight-wide design” that’s generally designed to sustain one bundle per clock.
My interpretation of this is that Tachyum can pull up to 4 bundles from the L1i which can be broken up into 2 micro-ops at decode for 8 micro-ops per cycle. However, another, more pessimistic, interpretation based on what MPR says is that only one bundle can be broken per cycle and that there can be up to 4 micro-ops in that bundle.
After bundles are fetched, they’re placed into a 12-entry queue. This queue can let the frontend keep fetching instructions even when the backend is stalled and isn’t ready to accept them. If instructions are queued up from a backend stall, the frontend can “hide” an instruction cache miss by continuing to feed the backend with those queued up instructions while waiting for instruction bytes from lower-level caches. I assume Prodigy’s queue holds 12 bundles, not 12 micro-ops. If each bundle is filled to its maximum capacity of eight micro-ops, the queue can hold a total of 96 micro-ops.
In HC2018, Tachyum suggests that each bundle has 2.6 instructions on average. Thus, the queue’s effective capacity will likely be below 32 micro-ops in practice. For comparison, Skylake gives each SMT thread a 25-entry instruction buffer after the fetch stage and a 64-entry micro-op queue after the decoders. That’s a lot more buffering capability than Prodigy, which will make Skylake’s frontend more robust with absorbing stalls.
So with the front end of Prodigy covered, let’s talk about those Out of Order claims.

Tachyum claims that they can achieve Out-of-Order execution with In-Order power and area which at first seems like an unfeasible claim, but dive a bit deeper and there may be a way for this claim to be true. Tachyum talks about something they call “poison bits” to extract ILP. We don’t quite know what that means but we suspect that Tachyum is using a technique similar to something outlined in this paper called iCFP that was found by Camacho who is a member of the Chips and Cheese discord. iCFP is a technique where you have a slice buffer and checkpoints and if you have a cache miss you replay in a manner similar to Netburst which we have covered previously. Now, iCFP does have limits to what it can make Out-of-Order but calling it OoO execution is, in my opinion, fair.
That’s because iCFP solves the Achilles heel of in-order designs: stalling when an instruction consumes the result of a cache miss. In a conventional out-of-order design, a scheduler holds instructions waiting to execute. If an instruction needs a load result, it sits in the scheduler until data arrives and makes it ready to execute. However, a scheduler is expensive because potentially every instruction sitting in it has to be checked for execution-readiness every cycle. iCFP does away with this power and area hungry structure by moving cache miss-dependent (poisoned) instructions into a separate “slice” buffer and replaying them when the appropriate data arrives.
“Replay” may trigger memories of Netburst’s ill-fated approach to cache miss handling. But unlike Netburst, which continuously replays instructions until data arrives, a competent iCFP implementation should be able to only wake up the appropriate “slice” buffer when data arrives. That would greatly reduce power and execution unit wastage from excessive replay, especially with longer latency cache misses.
But nothing comes for free, and iCFP does need large buffers to track instructions waiting for cache misses, along with all their dependencies. Still, this could be a promising path. Research suggests that iCFP can largely match small out-of-order architectures with lower area requirements:

As always, new microarchitecture techniques are dangerous. Intel struggled with Netburst even though most of the new techniques tried had debuted earlier in other companies’ CPUs. For example, DEC’s Alpha EV5 used a PRF-based out-of-order execution scheme. If Tachyum is indeed going after iCFP, saying that it’s a risky approach would be an understatement. To our knowledge, iCFP has not been implemented before. And it’s worth remembering that there was promising research about trace caches in the years leading up to Netburst’s debut.

Yet as we all know, the idea of caching traces led to inefficient use of instruction cache capacity and ultimately doomed it. A similarly missed deficiency could do the same to iCFP. Finally, Tachyum has not said much to suggest iCFP is in use, beyond saying poison bits were used to extract ILP. There’s no mention of large instruction buffers or checkpointing mechanisms that would definitely point to iCFP.
If iCFP is not in use, Prodigy’s performance per clock prospects look dim. The architecture would stall when the result of a cache miss is consumed, like other in-order CPUs today. This could be particularly devastating when running existing binaries over an emulation layer (like QEMU, as demo-ed by Tachyum).

With binaries that haven’t been compiled with in-order restrictions in mind, effective reordering capacity without iCFP (just nonblocking loads) will be nowhere near that of high-performance CPUs with out-of-order execution. That in turn means Prodigy would have a difficult time hiding latency from L1D misses.
What has changed?
Vector Execution
2018 Prodigy had an already quite beefy vector execution engine of two 512b vector FMAs per clock. 2022 Prodigy brought that up to two 1024b vector FMAs per clock along with also doubling the matrix throughput to two 2048b FMAs per clock from two 1024b FMAs per clock. That makes Prodigy the single largest FPU implementation per core of any general-purpose CPU, far surpassing any AMD, Arm, IBM or Intel CPU currently on the market. However, those large vector units come at the price of both die area and power consumption which we’ll talk about a little later.

Cache Subsystem
Feeding the cores with instructions and data is one of the biggest challenges facing modern CPU designers. Like Intel and AMD, Tachyum has opted for a three-level cache hierarchy for Prodigy.
2018 Prodigy only had 16KB of L1 data cache and 16KB of L1 instruction cache per core which was, to put it bluntly, pathetically small. 2018 Prodigy also only had 256KB of L2 per core which is also quite small with the last level being a 32MB L3 that was shared amongst 64 cores. However, there seems to have been a revision of Prodigy in either 2020 or 2021 that doubled both the L1s and the L2 to 32KB and 512KB respectively along with doubling the core counts to 128 and with that also doubled the L3 to 64MB. With 2022 Prodigy, Tachyum has once again doubled both the L1s and the L2 to 64KB and 1MB. But in a large change to the cache hierarchy, Tachyum uses a virtual L3 instead of a physical L3 for 2022 Prodigy much like how IBM does the L3 for Telum.
For the L3 victim cache, Tachyum has opted for a dynamic solution that is somewhat reminiscent of the virtual third buffer level of IBM’s Telum (z16): “The L3 is virtually the L2, inactive cores give up their resources,” the CEO reveals.
From the Golem.de interview with Radoslav Danilak, quote has been translated in to English from German by Google Translate
A virtual L3 cache like what IBM implemented on Telum has the benefit of not needing the physical space that a more traditional L3 needs. That’s because a single block of cache can act as either L2 or L3, removing the need for a separate L2. It also takes advantage of faster access to a core’s local L3 slice – something that isn’t done in Intel, AMD or Arm’s distributed L3 setups.
However, a virtual cache could be complicated to pull off. You have to decide how to distribute SRAM capacity between the L2 and L3. The 2022 Prodigy core also doesn’t have much L2 to go around. It has 1MB of L2 per core compared to Telum’s 32MB. Prodigy also falls short on last-level cache capacity compared to AMD’s Milan, which has 4 MB of L3 per core. A dedicated L4 victim cache (or L3, making the virtual L3 cache an “L2.5” if you will) might also help alleviate this pressure if lots of lines end up getting kicked out prematurely. But Prodigy doesn’t have this. This less effective L3 could mean that Prodigy will struggle with keeping those massive vector units fed unless the DRAM setup can pull off some magic.
DRAM Setup
At least on paper, Prodigy can do this to some extent. The chip has a massive memory and IO setup. With extremely high-speed DDR5, Tachyum claims they can pull in a terabyte of data from DRAM every second – something only high-end GPUs and other accelerators can approach.

However, even this might not be enough. Compared to CPUs and GPUs used in high-performance computing, Prodigy’s compute-to-memory-bandwidth ratio is quite low.
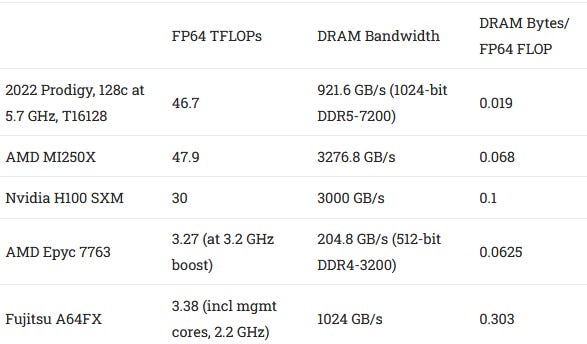
That could make Prodigy bandwidth starved and difficult to optimize for. Programmers looking to exploit its wide vector units will have to make sure most of the data can be pulled from the cache, but Prodigy doesn’t have much cache per core. In comparison, AMD’s EPYC 7763 has 292MB of SRAM when counting the L1, L2, and L3, whereas the T16128 only has a total of 144MB of SRAM. This lack of SRAM is likely due to Tachyum prioritizing core count and vector execution width over their caching strategy. The lack of SRAM capacity in turn dictates using techniques like a virtual L3, to try to make what little cache they have go as far as possible.
The I/O for Prodigy has also changed quite a bit between 2018 and 2022 as well.

With 2022 Prodigy, Tachyum has chosen to remove both the HBM and Ethernet interfaces but in return, they have made a consistent PCIe setup along with doubling the DDR5 memory bus.
Using DDR5-7200 on a 1024b DDR5 interface would net you 921.6 GB/s of memory bandwidth which is double the estimated memory bandwidth of Genoa at 460.8 GB/s using a 768b memory bus running at DDR5-4800. This is very good for a server CPU but this is still behind A64FX’s 1TB/s of memory bandwidth using 4 stacks of HBM2E while trying to feed far more compute. What also doesn’t look good is the 64 lanes of PCIe 5.0 that Prodigy has, as this could really limit it in I/O heavy workloads such as Netflix’s use-case of using an array of 18 PCIe SSDs in each server to maximize bandwidth which 2022 Prodigy couldn’t handle with its current PCIe configuration.
Node, Power, Area, and Clocks
2018 Prodigy was going to use TSMC’s then brand new N7 node with a power consumption of 180 watts and 280 square millimeters for 64 cores running at over 4 GHz which is very high for a server CPU. Extrapolating this out to a 128-core version would make this a 360-watt CPU with a die area of 560 square millimeters on N7.
2022 Prodigy is a whole different beast. Taping out on TSMC’s N5 node, 2022 Prodigy will be a 950 watt 128 core behemoth running at clocks up to 5.7 GHz all of which will be in an area that is around 500 square millimeters.

To start with, 950W in a 500 square millimeter package has a thermal density of nearly 2 watts per square millimeter across the whole chip, which is over double Nvidia’s H100’s 0.875 watts per square millimeter thermal density across the whole chip. This will take some incredibly beefy cooling to say the least and just won’t be feasible for some datacenters.
So take a look at the lower power SKUs and you start to see something odd with the TDP numbers, core counts, and clock speeds. Somehow the T864-HS is the same power as the T832-HS yet has double the core count, and it is the same story with the T16128-HT and T864-HT SKUs as well. Then looking at the T16128-HT and T16128-AIE SKUs, somehow the T16128-HT clocks higher while having half the TDP of the T16128-AIE.
Now, these reported clocks are boost clocks according to Danilak.
“The values include an artificial throttling of the clock in order to act within the TDP.”
Radoslav Danilak, CEO of Tachyum
However, I have doubts that Prodigy will even be able to hit these clocks on more than 1 or 2 cores doing integer workloads. Trying to drive those massive vector execution units at 5.7GHz will need a ton of power, likely far beyond what Tachyum is quoting. I also have to doubt that Tachyum will somehow get all that vector and matrix execution into a die area around 500 square millimeters.
Beyond the Hardware
With any new ISA, you need to build the software system up to support your brand new, all-singing, all-dancing, ISA. And that is where yet more issues for Tachyum crop up. The x86 ISA owes its success to having the strongest software ecosystem around. Arm is emerging as a competitive option, but it took years to build up the Arm software ecosystem to get it anywhere close. And still, Arm suffers from gaps like lack of proper vectorization in encoders for new video codecs, or applications distributed in binary form that require translation and incur a performance penalty. But those teething problems will look like nothing compared to what’s facing Tachyum because they’re starting from ground zero.
As far as anything public-facing goes, there have been no updates to any of the major compilers with Tachyum saying that their optimizations to GCC will be upstreamed in Q4 this year and there have been no commits to LLVM either.
Worse, Tachyum’s ISA is very closely tied to the hardware implementation, in order to reduce decoding and scheduling costs as much as possible. Each bundle contains a mix of instructions that closely correspond to Prodigy’s execution units. That makes the ISA inflexible. For example, implementing a new core with three FMA units would be extremely awkward because the existing bundle design can only hold two FMA instructions. The new core could of course break the bundles apart and schedule individual RISC ops. That’s what Poulson-based Itaniums did. But then Tachyum would lose the benefits of having an ISA closely tied to hardware.

When Tachyum says that they can run x86, ARM, and RISC-V binaries, they are using QEMU emulation to run those programs. That means that Prodigy’s performance is going to be reduced to the point of irrelevance. This Geekbench comparison sums it up neatly, on average you lose almost 90% of your performance for single-threaded tasks and over 80% of your performance for multithreaded tasks with, ironically enough, SIMD tasks suffering the most from QEMU.
Conclusion
Returning to that old proverb, Prodigy really seems to be too good to be true. Tachyum is promising that Prodigy will be able to be everything to everyone and that simply is not possible in the 500 square millimeter package that Tachyum says that Prodigy fits in. I would go as far as to say that either everyone in the semiconductor industry is blithering idiots and Tachyum is staffed by pure geniuses or that Tachyum’s claims just aren’t possible. And if I was a betting man, my money would go to the latter.
If Tachyum was positioning Prodigy as a specialized supercomputer part, in the same manner as Fujitsu’s A64FX, then I could see this as having a niche market. But they aren’t doing that at all, they are calling this a universal processor that can do everything. AMD’s newly announced MI300 is also claiming to be a “Datacenter APU” and do everything that Prodigy can do, the difference being that: AMD is a proven company unlike Tachyum, AMD has been building up to a product like MI300 ever since the launch of HSA, MI300 is going to be much much larger than 500 square millimeters which means that it is nowhere near as area constrained, and while AMD’s compute stack is a mess right now at least they have one versus Tachyum’s seemingly non-existent stack which is critical to a VLIW architecture. And to add insult to injury, Tachyum removed the originally planned HBM controllers for more DDR5 controllers which have to run at a currently completely unrealistic speed of DDR5-7200 to get close to A64FX’s 1 TB/s of memory bandwidth. Whereas, had Tachyum stuck with the 2 HBM3 controllers they could have potentially had a pool of 48 GB of memory running at over 1.6 TB/s of memory bandwidth along with 8 channels of DDR5 acting as a much larger but slower memory pool for a total of roughly 2TB/s of memory bandwidth; not to mention that they would have had to only feed a quarter the compute in the original 2018 64 core Prodigy with the 2TB/s memory configuration or half the compute with possibly 4TB/s of memory bandwidth with 2018’s 128 core Prodigy which was 2 64-core dies on the same package.
Prodigy has to feed up to 45TFlops of FP64 Vector compute with less than 1TB/s of memory bandwidth which is an over 50-to-1 FP64 Vector Compute to Memory Bandwidth ratio. For a comparison, MI250X having both similar amounts of FP64 Vector compute (47.8TFlops) and total SRAM amount (~156.25MB for MI250X versus ~144MB for Prodigy) has over 3.5 times the memory bandwidth to feed that massive FP64 compute which puts MI250X at an FP64 Vector Compute to Memory Bandwidth ratio of just under 15:1. And the specialized HPC CPU A64FX is at an FP64 Vector Compute to Memory Bandwidth ratio of 3.4:1.

{kind=link}
Tachyum claims to be taping out Prodigy in “the second half of the third quarter“ with sampling starting in December and production in H1 2023. This seems very optimistic for a company that has never taped out a chip before. However, if we do assume that Prodigy can move to production in H1 2023, then it will have to fight both NVIDIA’s Grace-Hopper Superchip along with the previously mentioned MI300 from AMD and both those chips will most likely beat Prodigy’s performance at lower power.
Tachyum also says that they are planning a Prodigy 2 on TSMC’s N3 process which will have support for more cores, PCIe 6.0, and CXL. But Prodigy 2 will not be sampling until H2 2024 which means that it is competing with next-gen products from AMD, Intel and Nvidia which will most likely render Prodigy 2 redundant.
Tachyum really has put itself into a tough spot. Had they been able to live up to their timeline of having production silicon out in 2020, they would have had a very uphill battle ahead of them but one that they could have won. But it is now 2022 and that hill is looking more like a 90-degree cliff face that is simply insurmountable. We here at Chips and Cheese love to see the underdog come out of nowhere and beat the reigning champions. But I suspect that won’t be the case with Tachyum.
If you like our articles and journalism and you want to support us in our endeavors then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way or if you would like to talk with the Chips and Cheese staff and the people behind the scenes then consider joining our Discord.