
Centaur CHA’s Probably Unfinished Dual Socket Implementation

Centaur’s CHA chip targets the server market with a low core count. Its dual socket capability is therefore quite important, because it’d allow up to 16 cores in a single CHA-based server. Unfortunately for Centaur, modern dual socket implementations are quite complicated. CPUs today use memory controllers integrated into the CPU chip itself, meaning that each CPU socket has its own pool of memory. If CPU cores on one socket want to access memory connected to another socket, they’ll have to go through a cross-socket link. That creates a setup with non-uniform memory access (NUMA). Crossing sockets will always increase latency and reduce bandwidth, but a good NUMA implementation will minimize those penalties.

Cross-Socket Latency
Here, we’ll test how much latency the cross-socket link adds by allocating memory on different nodes, and using cores on different nodes to access that memory. This is basically our latency test being run only at the 1 GB test size, because that size is large enough to spill out of any caches. And we’re using 2 MB pages to avoid TLB miss penalties. That’s not realistic for most consumer applications, which use 4 KB pages, but we’re trying to isolate NUMA-related latency penalties instead of showing memory latency that applications will see in practice.

Crossing sockets adds about 92 ns of additional latency, meaning that memory on a different socket takes almost twice as long to access. For comparison, Intel suffers less of a penalty.

On a dual socket Broadwell system, crossing sockets adds 42 ns of latency with the early snoop setting. Accessing remote memory takes 41.7% longer than hitting memory directly attached to the CPU. Compared to CNS, Intel is a mile ahead, partially because that early snoop mode is optimized for low latency. The other part is that Intel has plenty of experience working on multi-socket capable chips. If we go back over a decade to Intel’s Westmere based Xeon X5650, memory access latency on the same node is 70.3 ns, while remote memory access is 121.1 ns. The latency delta there is just above 50 ns. It’s worse than Broadwell, but still significantly better than Centaur’s showing.
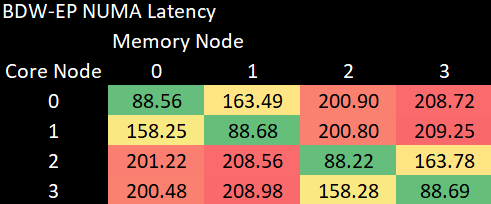
Broadwell also supports a cluster-on-die setting, which creates two NUMA nodes per socket. In this mode, a NUMA node covers a single ring bus, connected to a dual channel DDR4 memory controller. This slightly reduces local memory access latency. But Intel has a much harder time with four pools of memory in play. Crossing sockets now takes almost as long as it does on CHA. Looking closer, we can see that memory latency jumps by nearly 70 ns when accessing “remote” memory connected to the same die. That’s bigger than the cross-socket latency delta, and suggests that Intel takes a lot longer to figure out where to send a memory request if it has three remote nodes to pick from.
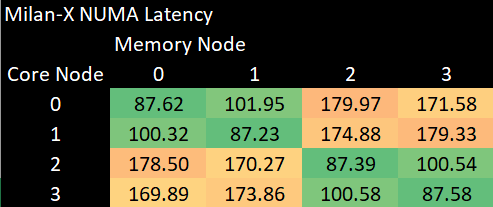
Popping over to AMD, we have results from when we tested a Milan-X system on Azure. Like Broadwell’s cluster on die mode, AMD’s NPS2 mode creates two NUMA nodes within a socket. However, AMD seems to have very fast directories for figuring out which node is responsible for a memory address. Going from one half of a socket to another only adds 14.33 ns. The cross socket connection on Milan-X adds around 70-80 ns of latency, depending on which half of the remote socket you’re accessing.
To summarize, Centaur’s cross-node latency is mediocre. It’s worse than what we see from Intel or AMD, unless the Intel Broadwell system is juggling four NUMA nodes. But it’s not terrible for a company that has no experience in multi-socket designs.
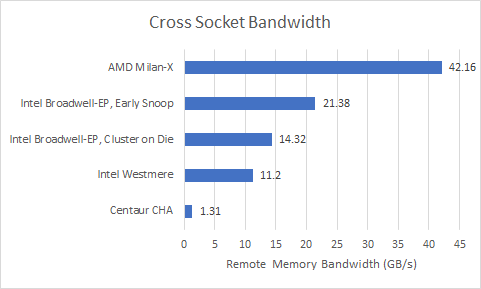
Cross-Socket Bandwidth
Next, we’ll test bandwidth. Like with the latency test, we’re running our bandwidth test with different combinations of where memory is allocated and what CPU cores are used. The test size here is 3 GB, because that’s the largest size we have hardcoded into our bandwidth test. Size doesn’t really matter as long as it’s big enough to get out of caches. To keep things simple, we’re only testing read bandwidth.

Centaur’s cross socket bandwidth is disastrously poor at just above 1.3 GB/s. When you can read faster from a good NVMe SSD, something is wrong. For comparison, Intel’s decade old Xeon X5650 can sustain 11.2 GB/s of cross socket bandwidth, even though its triple channel DDR3 setup only achieved 20.4 GB/s within a node. A newer design like Broadwell does even better.

With each socket represented by one NUMA node, Broadwell can get nearly 60 GB/s of read bandwidth from its four DDR4-2400 channels. Accessing that from a different socket drops bandwidth to 21.3 GB/s. That’s quite a jump over Westmere, showing the progress Intel has made over the past decade.
If we switch Broadwell into cluster on die mode, each node of seven cores can still pull more cross-socket bandwidth than what Centaur can achieve. Curiously, Broadwell suffers a heavy penalty from crossing nodes within a die, with memory bandwidth cut approximately in half.

Finally, let’s have a look at AMD’s Milan-X:

Milan-X is a bandwidth monster compared to the other chips here. It has twice as many DDR4 channels as CHA and Broadwell, so high intra-node bandwidth comes as no surprise. Across nodes, AMD retains very good bandwidth when accessing the other half of the same socket. Across sockets, each NPS2 node can still pull over 40 GB/s, which isn’t far off CHA’s local memory bandwidth.
Core to Core Latency with Contested Atomics
Our last test evaluates cache coherency performance by using locked compare-and-exchange operations to modify data shared between two cores. Centaur does well here, with latencies around 90 to 130 ns when crossing sockets.

The core to core latency plot above is similar to Ampere Altra’s, where cache coherency operations on a cache line homed to a remote socket require a round trip over the cross-socket interconnect, even when the two cores communicating with each other are on the same chip. However, absolute latencies on CHA are far lower, thanks to CHA having far fewer cores and a less complex topology.
Intel’s Westmere architecture from 2010 is able to do better than CHA when cache coherency goes across sockets. They’re able to handle cache coherency operations within a die (likely at the L3 level) even if the cache line is homed to a remote socket.
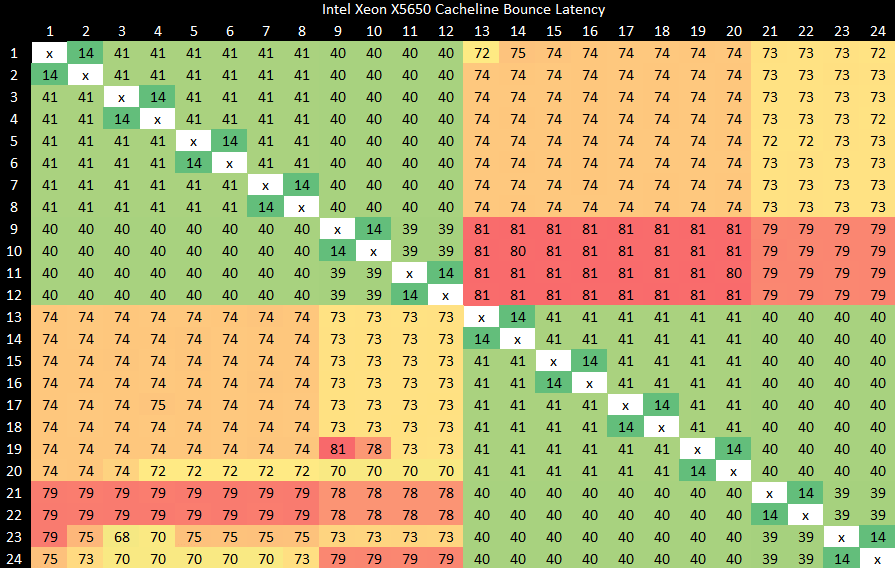
But this sort of excellent cross socket performance isn’t typical. Westmere likely benefits because all off-core requests go through a centralized global queue. Compared to the distributed approach used since Sandy Bridge, that approach suffers from higher latency and low bandwidth for regular L3 accesses. But its simplicity and centralized nature likely enables excellent cross-socket cache coherency performance.

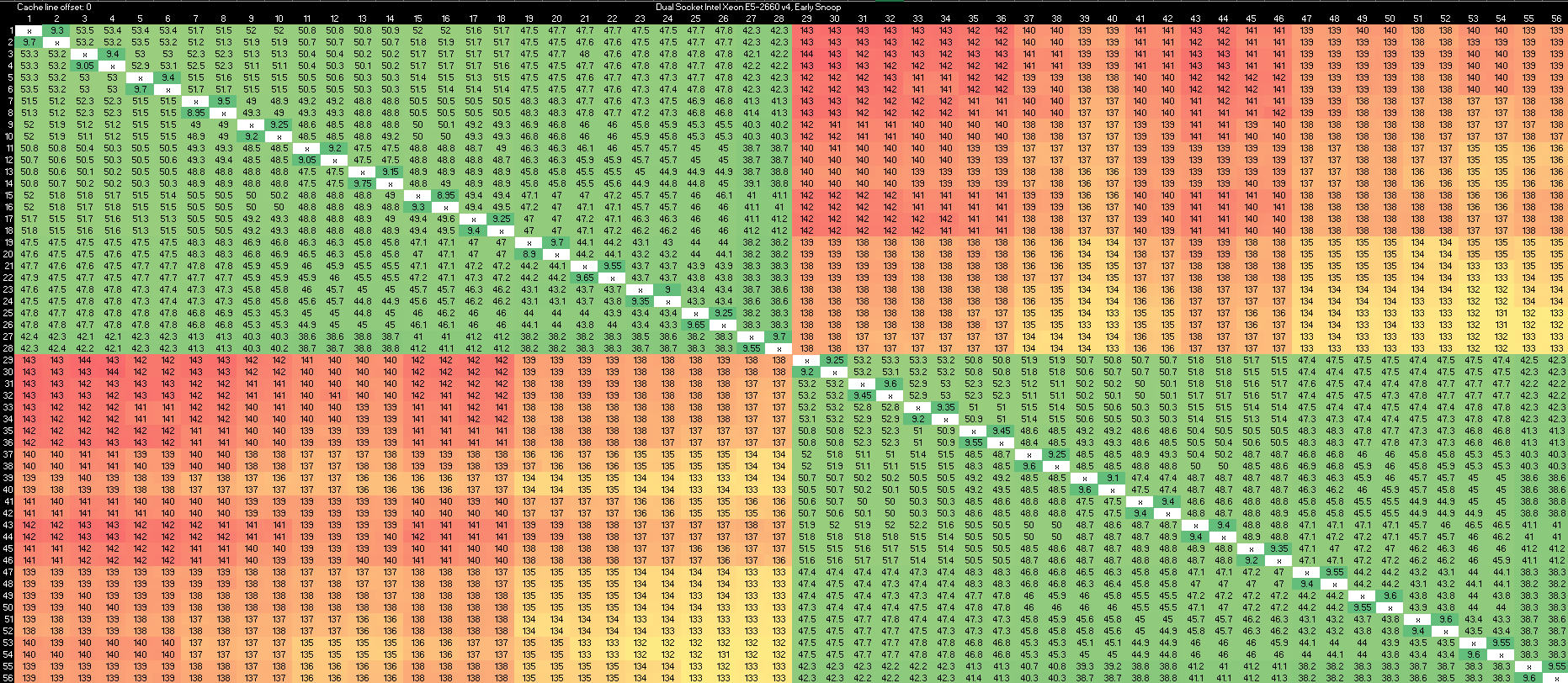
Broadwell’s cross-socket performance is similar to CHA’s. By looking at results from both cluster and die and early snoop modes, we can clearly see that the bulk of core to core cache coherence latency comes from how directory lookups are performed. If the transfer happens within a cluster on die node, coherency is handled via the inclusive L3 and its core valid bits. If the L3 is missed, the coherency mechanism is much slower. Intra-die, cross-node latencies are already over 100 ns. Crossing dies only adds another 10-20 ns.
Early snoop mode shows that intra-die coherency can be quite fast. Latencies stay within the 50 ns range or under, even when rings are crossed. However, early snoop mode increases cross socket latency to about 140 ns, making it slightly worse than CNS’s.
We don’t have clean results from Milan-X because hypervisor core pinning on the cloud instance was a bit funky. But our results were roughly in line with Anandtech’s results on Epyc 7763. Intra-CCX latencies are very low. Cross-CCX latencies within a NPS2 node were in the 90 ns range. Crossing NPS2 nodes brought latencies to around 110 ns, and crossing sockets resulted in ~190 ns latency.
{kind=link}
Centaur’s cross socket performance in this category is therefore better than Epyc’s. More generally, CHA puts in its best showing in this kind of test. It’s able to go toe to toe with AMD and Intel systems that smacked it around in our “clean” memory access tests. “Clean” here means that we don’t have multiple cores writing to the same cache line.
Unfortunately for Centaur, we’ve seen exactly zero examples of applications that benefit from low core-to-core latency. Contested atomics just don’t seem to be very common in multithreaded code.
Final Words
Before CNS, Centaur focused on low power consumer CPUs with products like the VIA Nano. Some of that experience carries over into server designs. After all, low power consumption and small core size are common goals. But go beyond the cpu core, and servers are a different world.
Servers require high core counts, lots of IO, and lots of memory bandwidth. They also need to support high memory capacity. CHA delivers on some of those fronts. It can support hundreds of gigabytes of memory per socket. Its quad channel DDR4 memory controller and 44 PCIe lanes give adequate but not outstanding off-chip bandwidth. CHA is also the highest core count chip created by Centaur. But eight cores is a bit low for the server market today. Dual socket support could partially mitigate that.
Unfortunately, the dual socket work appears to be unfinished. CHA’s low cross socket bandwidth will cause serious problems, especially for NUMA-unaware workloads. It also sinks any possibility of using the system in interleaved mode, where accesses are striped across sockets to provide more bandwidth to NUMA-unuaware applications at the expense of higher latency.
So what went wrong? Well, remember that cross socket accesses suffer extra latency. That’s common to all platforms. But achieving high bandwidth over a long latency connection requires being able to queue up a lot of outstanding requests. My guess is that Centaur implemented a queue in front of their cross socket link, but never got around to validating it. Centaur’s small staff and limited resources were probably busy covering all the new server-related technologies. What we’re seeing is probably a work in progress.

Centaur has implemented the protocols and coherence directories necessary to make multiple sockets work. And they work with reasonably good latency. Unfortunately, the cross-socket work can’t be finished because Centaur doesn’t exist anymore, so we’ll never see CHA’s full potential in a dual socket setup.
Special thanks to Brutus for setting the system up and running tests on it.
If you like our articles and journalism and you want to support us in our endeavors then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way or if you would like to talk with the Chips and Cheese staff and the people behind the scenes then consider joining our Discord.