
Alder Lake – E-Cores, Ring Clock, and Hybrid Teething Troubles

This will be a short post about how Alder Lake’s ring behaves when E-Cores are active. With just P-Cores active, the ring runs at 4.7 GHz. But if anything is running on the E-Cores, the ring frequency drops to 3.6 GHz. This drop happens regardless of whether the E-Cores are accessing L3/memory. That in turn impacts L3 and memory performance from the big cores.
To characterize these effects, we ran our latency and bandwidth tests with and without a dummy load running on a single Gracemont core. This dummy load consists of a small loop of NOPs, which means the Gracemont core is only reading from its instruction cache and doing nothing else. Most importantly, the Gracemont core isn’t accessing L3 or memory.
Effect on Cache and Memory Latency
The slower ring clock introduces about a 11.7% latency penalty in L3 sized regions, or about a 1.78 ns difference. Once we hit memory, there’s a 3.4 ns difference, or 3.7% higher latency.
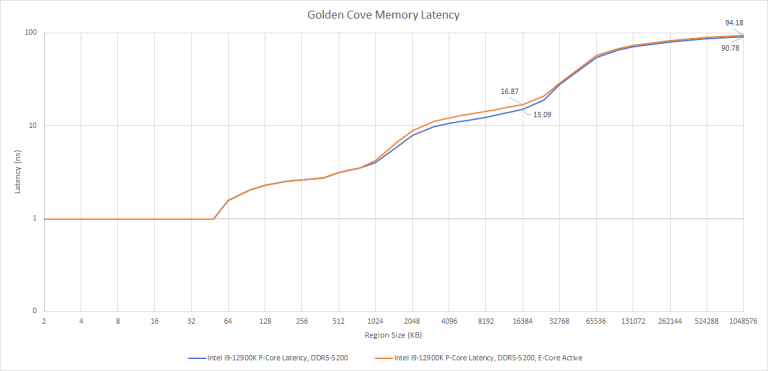
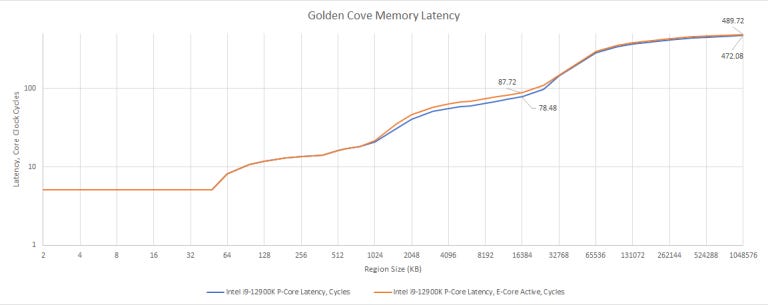
We can also look at latency impact in terms of cycles. Having an E-Core active increases latency by 9-10 cycles. With this additional latency, Golden Cove might have more trouble absorbing the latency of a demand L3 access. That in turn would increase its reliance on core-private caches and prefetching to keep its instruction throughput up.
Loading an E-Core also introduces a measurable drop in L3 bandwidth, of around 20%
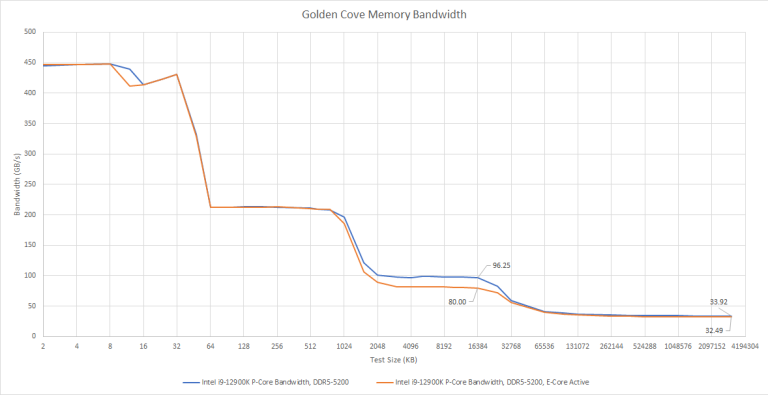
Memory bandwidth is slightly affected. But like the latency situation, it’s a small 3.2% difference. Next, let’s examine bandwidth across all the P-Cores, with one thread per core:
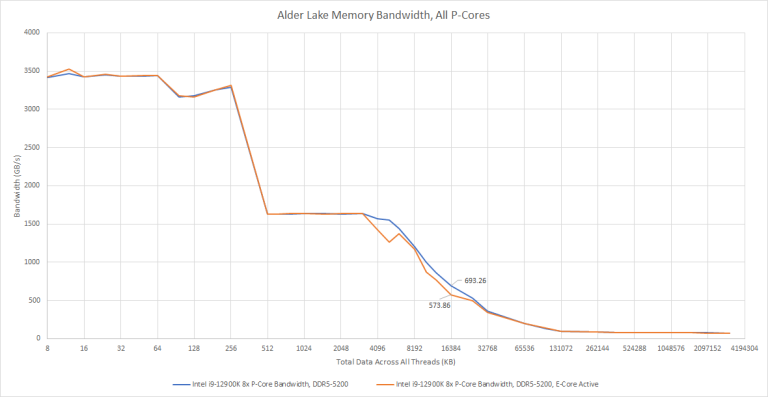
Again we see a 20% drop in L3 bandwidth. However, memory bandwidth is unaffected. At the 3 GB test size, leaving an E-Core active reduced bandwidth by 0.05% – well within run to run variation.
Performance Impact
Now, let’s run a couple benchmarks on the P-Cores, with and without that dummy load on an E-Core. Both of these were run with affinity set to the P-Cores, with one thread per core.
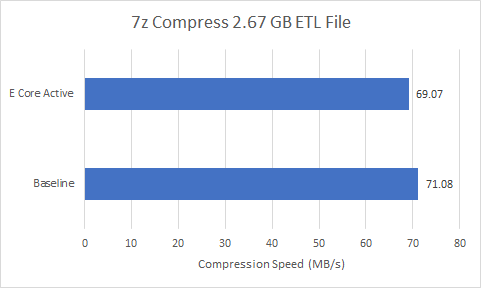
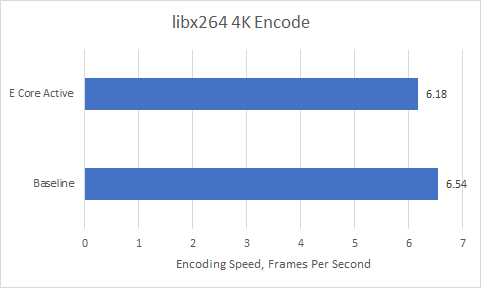
Thankfully, the performance impact is low in both cases. Keeping the E-Cores idle improved compression performance by 2.9%, and encoding performance by 5.8%. While measurable, you’d have to be looking at a stopwatch to notice the difference. Furthermore, the loss of big core performance can easily be offset by the increased throughput offered by the Gracemont cores.
Comments
Alder Lake’s hybrid design pushes the flexibility of Intel’s ring bus, and is a showcase of Intel’s modular design. But first attempts at new things often encounter teething problems. Alder Lake seems to be no exception. The software side has been well covered, but the hardware side is not flawless either. We expect Intel to improve on their hybrid architecture going forward as they get more experience and improving on this aspect with Alder Lake’s follow on, codename Raptor Lake, seems to be a goal for Intel as the leaked Raptor Lake slides indicated. If you like our articles and journalism and you want to support us in our endeavors then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way.
This is a great write-up and I hope you do same tests with recent Intel SKUs.
IMO these tests are very important for consumers caring not just about parallel processing.
Would be interesting to know how AVX512 mixes in when Intel finally manages to add it to E-cores or make the limitation of instruction set more transparent to the OS.