
ARM or x86? ISA Doesn’t Matter

For the past decade, ARM CPU makers have made repeated attempts to break into the high performance CPU market so it’s no surprise that we’ve seen plenty of articles, videos and discussions about ARM’s effort, and many of these pieces focus on differences between the two instruction set architectures (ISAs).
Here in this article we’ll bring together research, comments from people who are very familiar with CPUs, and a bit of our in-house data to show why focusing on the ISA is a waste of time(1) and to start us off on our little adventure, let’s reference Anandtech’s interview of Jim Keller, an engineer who worked on several successful CPU designs including AMD’s Zen and Apple’s A4/A5.
[Arguing about instruction sets] is a very sad story.
An AnandTech Interview with Jim Keller: ‘The Laziest Person at Tesla’
CISC vs RISC: An Outdated Debate
x86 was historically categorized as a CISC (Complex Instruction Set Computer) ISA, while ARM was categorized as RISC (Reduced Instruction Set Computer). Originally, CISC machines aimed to execute fewer, more complex instructions and do more work per instruction. RISC used simpler instructions that are easier and faster to execute. Today, that distinction no longer exists. In Jim Keller’s words:
When RISC first came out, x86 was half microcode. So if you look at the die, half the chip is a ROM, or maybe a third or something. And the RISC guys could say that there is no ROM on a RISC chip, so we get more performance. But now the ROM is so small, you can’t find it. Actually, the adder is so small, you can hardly find it? What limits computer performance today is predictability, and the two big ones are instruction/branch predictability, and data locality.
An AnandTech Interview with Jim Keller: ‘The Laziest Person at Tesla’
In short, there’s no meaningful difference between RISC/ARM and CISC/x86 as far as performance is concerned. What matters is keeping the core fed, and fed with the right data which puts focus on cache design, branch prediction, prefetching, and a variety of cool tricks like predicting whether a load can execute before a store to an unknown address.
Researchers caught onto this way before Anandtech’s Jim Keller interview when in 2013, Blem et al. investigated the impact of ISA on various x86 and ARM CPUs[1], and found RISC/ARM and CISC/x86 have largely converged.
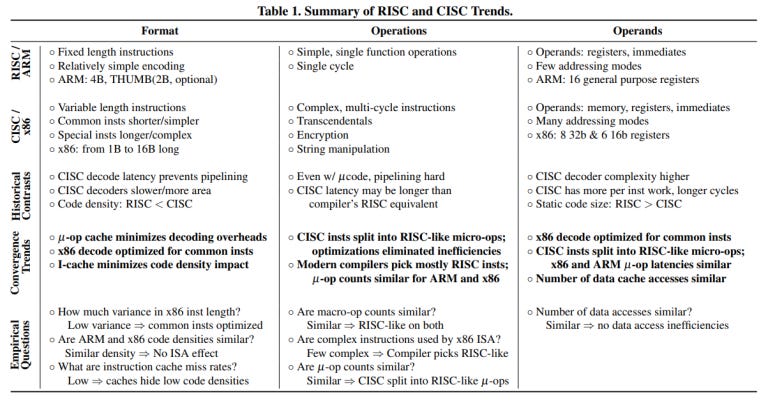
Blem et al. concluded that ARM and x86 CPUs differed in power consumption and performance mainly because they were optimized with different goals in mind. The instruction set isn’t really important here rather the design of the CPU implementing the instruction set is what matters:
The main findings from our study are:
– Large performance gaps exist across implementations, although average cycle count gaps are <= 2.5x.
– Instruction count and mix are ISA-independent to the first order.
– Performance differences are generated by ISA-independent microarchitectural differences.
– The energy consumption is again ISA-independent.
– ISA differences have implementation implications, but modern microarchitecture techniques render them moot; one ISA is not fundamentally more efficient.
– ARM and x86 implementations are simply design points optimized for different performance levelsPower Struggles: Revisiting the RISC vs. CISC Debate on Contemporary ARM and x86 Architectures
In other words, this very popular Techquickie video is misleading, and the ARM ISA doesn’t have anything to do with low power. Similarly, the x86 ISA has nothing to do with high performance. The ARM based CPUs we’re familiar with today happen to be low power, because makers of ARM CPUs target their designs toward cell phones and tablets. Intel and AMD’s x86 CPUs target higher performance, which comes with higher power.
To throw more cold water on the idea that ISA plays a significant role, Intel targeted low power with their x86 based Atom cores. A study done at the Federal University of Rio Grande do Sul [6] concluded that “for all test cases, the Atom-based cluster proved to be the best option for use of multi-level parallelism at low power processors.”
The two core designs that were being tested were ARM’s Cortex-A9 and Intel’s Bonnell core. Interestingly enough, Bonnell is an in-order design versus the Cortex-A9 which is an out of order design which should give both the performance and energy efficiency win to the Cortex-A9, yet in the tests that were used in the study Bonnell came out ahead in both categories.
Decoder Differences: A Drop in the Bucket
Another oft-repeated truism is that x86 has a significant ‘decode tax’ handicap. ARM uses fixed length instructions, while x86’s instructions vary in length. Because you have to determine the length of one instruction before knowing where the next begins, decoding x86 instructions in parallel is more difficult. This is a disadvantage for x86, yet it doesn’t really matter for high performance CPUs because in Jim Keller’s words:
For a while we thought variable-length instructions were really hard to decode. But we keep figuring out how to do that. … So fixed-length instructions seem really nice when you’re building little baby computers, but if you’re building a really big computer, to predict or to figure out where all the instructions are, it isn’t dominating the die. So it doesn’t matter that much.
An AnandTech Interview with Jim Keller: ‘The Laziest Person at Tesla’
Here at Chips and Cheese, we go deep and check things out for ourselves.
With the op cache disabled via an undocumented MSR, we found that Zen 2’s fetch and decode path consumes around 4-10% more core power, or 0.5-6% more package power than the op cache path. In practice, the decoders will consume an even lower fraction of core or package power. Zen 2 was not designed to run with the micro-op cache disabled and the benchmark we used (CPU-Z) fits into L1 caches, which means it doesn’t stress other parts of the memory hierarchy. For other workloads, power draw from the L2 and L3 caches as well as the memory controller would make decoder power even less significant.
In fact, several workloads saw less power draw with the op cache was disabled. Decoder power draw was drowned out by power draw from other core components, especially if the op cache kept them better fed. That lines up with Jim Keller’s comment.
Researchers agree too. In 2016, a study supported by the Helsinki Institute of Physics[2] looked at Intel’s Haswell microarchitecture. There, Hiriki et al. estimated that Haswell’s decoder consumed 3-10% of package power. The study concluded that “the x86-64 instruction set is not a major hindrance in producing an energy-efficient processor architecture.”
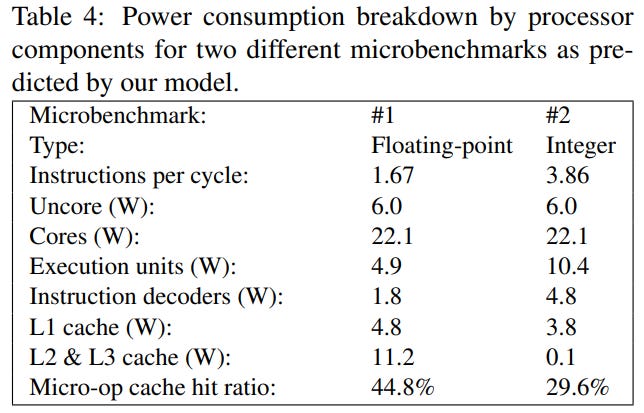
In yet another study, Oboril et al.[5] measured fetch and decode power on an Intel Ivy Bridge CPU. While that paper focused on developing an accurate power model for core components and didn’t directly draw conclusions about x86, its data again shows decoder power is a drop in the ocean.
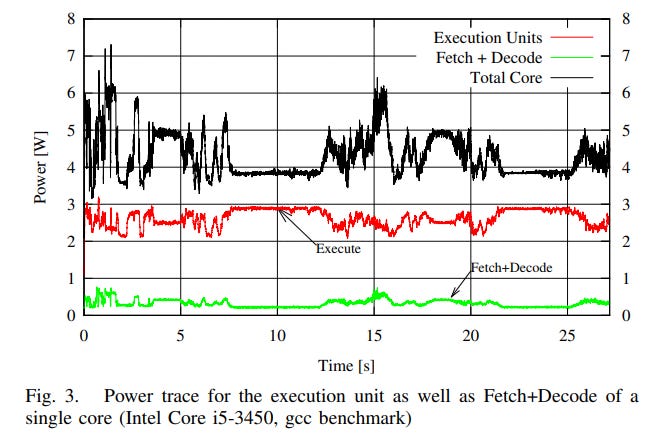
But obviously decoder power is nonzero, which means it’s an area of potential improvement. After all, every watt matters when you’re power constrained. Even on desktops, multithreaded performance is often limited by power. We’ve already seen x86 CPU architects use op caches to deliver a performance per watt win, so let’s take a look from the ARM side.
ARM Decode is Expensive Too
Hirki et al. also concluded that “switching to a different instruction set would only save a small amount of power since the instruction decoder cannot be eliminated in modern processors.”
ARM Ltd’s own designs are evidence of this. High performance ARM chips have adopted micro-op caches to skip instruction decoding, just like x86 CPUs. In 2019, the Cortex-A77 introduced a 1.5k entry op cache[3]. Designing an op cache isn’t an easy task – ARM’s team debugged their op cache design over at least six months. Clearly, ARM decode is difficult enough to justify spending significant engineering resources to skip decode whenever possible. The Cortex-A78, A710, X1, and X2 also feature op caches, showing the success of that approach over brute-force decode.
Samsung also introduced an op cache on their M5. In a paper detailing Samsung’s Exynos CPUs[4], decode power was called out as a motivation behind implementing an op cache:
As the design moved from supplying 4 instructions/uops per cycle in M1, to 6 per cycle in M3 (with future ambitions to grow to 8 per cycle), fetch and decode power was a significant concern.
The M5 implementation added a micro-operation cache as an alternative uop supply path, primarily to save fetch and decode power on repeatable kernels.
Just like x86 CPUs, ARM cores are using op caches to reduce decode cost. ARM’s “decode advantage” doesn’t matter enough to let ARM avoid op caches. And op caches will reduce decoder usage, making decode power matter even less.
And ARM Instructions Decode into Micro-Ops?
Gary Explains says the extra power used to split instructions into micro-ops on x86 CPUs is “enough to mean they’re not as power efficient as the equivalent ARM processors”, in the video titled “RISC vs CISC – Is it Still a Thing?“, he repeats this claim in a subsequent video.
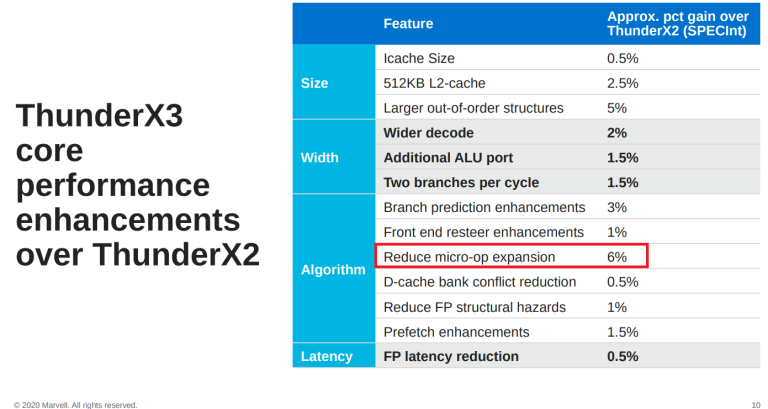
Gary is incorrect, as modern ARM CPUs also decode ARM instructions into multiple micro-ops. In fact, “reducing micro-op expansion” gave ThunderX3 a 6% performance gain over ThunderX2 (Marvell’s ThunderX chips are all ARM-based) which is more than any other reason in the breakdown.
We also took a quick look through the architecture manual for Fujitsu’s A64FX, the ARM based CPU that powers Japan’s Fugaku supercomputer. A64FX also decodes ARM instructions into multiple micro-ops.
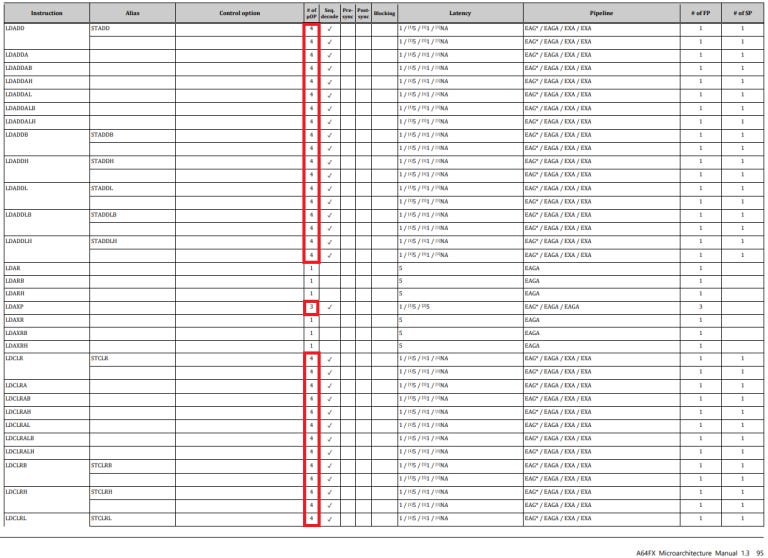
If we go further, some ARM SVE instructions decode into dozens of micro-ops. For example, FADDA (“floating point add strictly ordered reduction, accumulating in scalar”) decodes into 63 micro-ops. And some of those micro-ops individually have a latency of 9 cycles. So much for ARM/RISC instructions executing in a single cycle…
As another note, ARM isn’t a pure load-store architecture. For example, the LDADD instruction loads a value from memory, adds to it, and stores the result back to memory. A64FX decodes this into 4 micro-ops.
x86 and ARM: Both Bloated By Legacy
And it doesn’t matter for either of them.
In Anandtech’s interview, Jim Keller noted that both x86 and ARM both added features over time as software demands evolved. Both got cleaned up a bit when they went 64-bit, but remain old instruction sets that have seen years of iteration. And iteration inevitably brings bloat.
Keller curiously notes that RISC-V has no legacy, from being “early in the life cycle of complexity.” He continues:
If I want to build a computer really fast today, and I want it to go fast, RISC-V is the easiest one to choose. It’s the simplest one, it has got all the right features, it has got the right top eight instructions that you actually need to optimize for, and it doesn’t have too much junk.
An AnandTech Interview with Jim Keller: ‘The Laziest Person at Tesla’
If legacy bloat plays an important role, we can expect a RISC-V onslaught sometime soon, but I think that’s unlikely. Legacy support doesn’t mean that legacy support has to be fast; it can be microcoded, resulting in minimal die area use. Just like variable length instruction decode, that overhead is unlikely to matter in a modern, high performance CPU where die area is dominated by caches, wide execution units, large out-of-order schedulers, and big branch predictors.
Conclusion: Implementation Matters, not ISA
I’m excited to see competition from ARM. The high end CPU space needs more players, but ARM players aren’t getting a leg up over Intel and AMD because of instruction set differences. To win, ARM manufacturers will have to rely on the skill of their design teams. Or, they could outmaneuver Intel and AMD by optimizing for specific power and performance targets. AMD is especially vulnerable here, as they use a single core design to cover everything from laptops and desktops to servers and supercomputers.
That’s where we want to see the conversation go. Hopefully, the info presented here will avoid stuck-in-the-past debates about instruction sets, so we can move on to more interesting topics.
References
[1] Emily Blem, Jaikrishnan Menon, and Karthikeyan Sankaralingam, “Power Struggles: Revisiting the RISC vs. CISC Debate on Contemporary ARM and x86 Architectures”, HPCA 2013, hpca13-isa-power-struggles.pdf (wisc.edu)
[2] Mikael Hirki and Zhonghong Ou and Kashif Nizam Khan and Jukka K. Nurminen and Tapio Niemi, “Empirical Study of the Power Consumption of the x86-64 Instruction Decoder”, USENIX Workshop on Cool Topics on Sustainable Data Centers (CoolDC 16), cooldc16-paper-hirki.pdf (usenix.org)
[3] Vaibhav Agrawal, “Formal Verification of Macro-op Cache for Arm Cortex-A77, and its Successor CPU”, DVCON 2020, https://2020.dvcon-virtual.org/sites/dvcon20/files/2020-05/01_2_P.pdf
[4] Brian Grayson, Jeff Rupley, Gerald Zuraski Jr., Eric Quinnell, Daniel A. Jimenez, Tarun Nakra, Paul Kitchin, Ryan Hensley, Edward Brekelbaum, Vikas Sinha, and Ankit Ghiya, “Evolution of the Samsung Exynos CPU Microarchitecture”, ISCA, Evolution of the Samsung Exynos CPU Microarchitecture (computer.org)
[5]Fabian Oboril, Jos Ewert and Mehdi B. Tahoori, “High-Resolution Online Power Monitoring for Modern Microprocessors”, 2015 Design, Automation & Test in Europe Conference & Exhibition (DATE), Oboril15DATE.pdf (kit.edu)
[6]Vinicius Garcia Pinto, Arthur F. Lorenzon, Antonio Carlos S. Beck, Nicolas Maillard and Philippe O. A. Navau, “Energy Efficient Evaluation of Multi-level Parallelism on Low Power Processors”, CSBC 2014, csbc2014-wperformance.pdf (ufrgs.br)
Footnotes
(1) At least for common integer loads. ISA extensions can matter if workloads can take advantages of them. Notable examples include vector extensions like SSE/AVX/NEON/SVE, or encryption related extensions like AES-NI. Here’s an example of when ISA can matter:

Zen 2 (x86) and Ampere (ARM) are roughly in the same ballpark when compiling code, especially considering that Zen 2 is designed to hit higher performance targets (larger core structures, higher clock speeds).
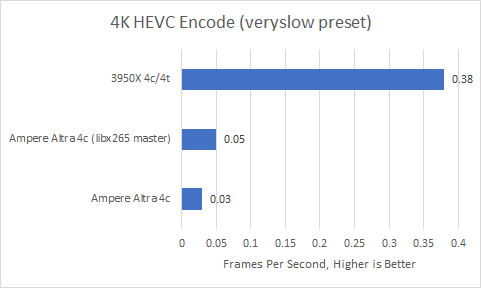
However, Ampere took more than half a day to transcode a 24 second 4K video while Zen 2 finished the job in just over an hour. Assembly optimizations weren’t being used for ARM, so I built the ffmpeg/libx265 from the latest master. With NEON instructions in use, Ampere’s performance improved by over 60%, cutting encode time to just over nine hours. But Ampere is still a country mile away from Zen 2.
Examining performance counters showed that Ampere executed 13.6x as many instructions as Zen 2 with Ubuntu 20.10’s stock ffmpeg, or 7.58x as many with bleeding-edge ffmpeg/libx265. Clearly Ampere executed simpler instructions and was able to do them faster, achieving 3.3 or 3.03 IPC respectively compared to Zen 2’s 2.35. Unfortunately, that does not compensate for having to crunch through an order of magnitude more instructions. It’s no wonder that the ARM instruction set has been extended to include more instructions (including complex ones) over time.
But that’s a topic for another day.
As far as ARM and x86 go today, both have rich ISA extensions that cover most use cases (implementation and software ecosystem support is another story).