
Exploring CPU Core to Core Latency and the Role that Locks Play

This article has been a LONG time coming since our article on Rocket Lake, where we talked about core to core latency for the first time here on Chips and Cheese. This is a follow up article exclusively about core to core latency.
The core to core latency tests used by us and Anandtech measure contested lock latency, specifically using atomic compare-and-set instructions. These instructions are used in multithreaded applications to enforce ordering between threads, including to implement higher level mutual exclusion locks.
When a thread executes a locked instruction (such as an atomic compare-and-set), it gets exclusive access to a block of data, usually a cache line, and guarantees the instruction will complete its memory operations without any other thread accessing the same memory. Now if another core wants to access that data for any reason, it must be transferred from the core that previously owned it. That’s how the core to core latency test works – two threads continuously try to execute atomic compare-and-set operations on the same data, forcing the cache line to be bounced between the two cores running the threads.
Of course, testing how a CPU performs in a core to core latency test says nothing about how that applies to real world applications. So we decided to test just how often locks cause core to core transfers in War Thunder, Time Spy, Overwatch, and our core to core latency using locks.
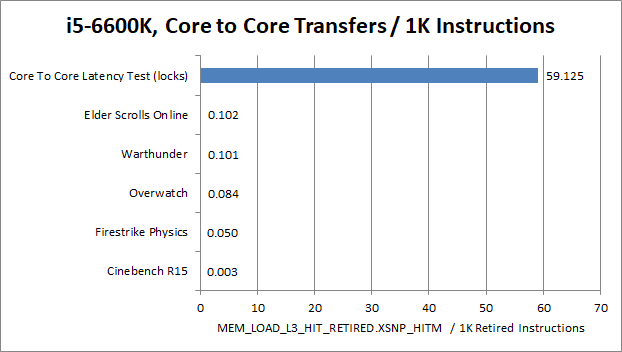
In the applications that we tested here, locks are a very rare occurrence with the exception of our Core to Core latency test. In all the applications we tested, contested locks affected 0.01% of instructions or less. In fact, core to core transfers are rarer than L3 cache misses. Typically games have around 20-30 per 10000 instructions suffering a L3 cache miss, which means that games are much more bound by memory latency than lock latency. If you picked an instruction at random, it’s 20-30 times more likely to miss L3 than require a core to core transfer. The situation is more skewed for very parallel productivity workloads like Cinebench, where L3 misses happen about 80x as often as core to core transfers.
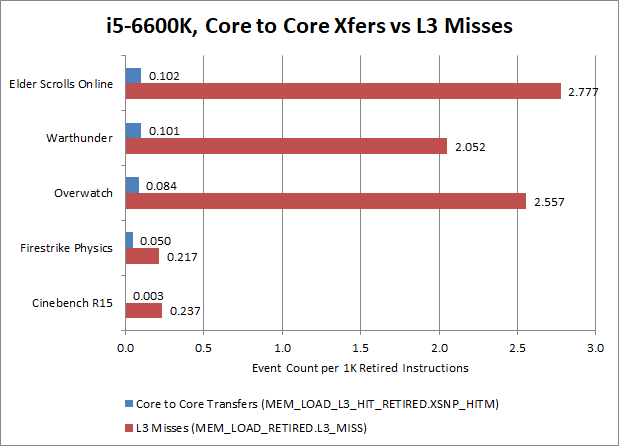
So in conclusion, a core to core latency test using locks isn’t very indicative of how a CPU will perform with real world usage either of games or productivity workloads. Core to core latency is merely one part of a CPU’s overall performance, and plays a small role compared to other factors like the performance of a CPU’s cache and memory hierarchy.
I would like to thank Clamchowder for writing all the tests and measurement applications used in this article and for helping me with the writing in this article.