
Measuring GPU Memory Latency

We’ve gotten used to measuring CPU cache and memory latencies, so why not do the same to GPUs? Like CPUs, GPUs have evolved to use multi-level cache hierarchies to address the growing gap between compute and memory performance. And like CPUs, we can use pointer chasing benchmarks (in OpenCL) to measure cache and memory latency.
Without further ado, welcome to the first from Chips and Cheese’s work-in-progress GPU memory latency test.
Ampere and RDNA 2

RDNA 2’s cache is fast and there’s a lot of it. Compared to Ampere, latency is low at all levels. Infinity Cache only adds about 20 ns over a L2 hit and has lower latency than Ampere’s L2. Amazingly, RDNA 2’s VRAM latency is about the same as Ampere’s, even though RDNA 2 is checking two more levels of cache on the way to memory.
In contrast, Nvidia sticks with a more conventional GPU memory subsystem with only two levels of cache and high L2 latency. Going from Ampere’s SM-private L1 to L2 takes over 100 ns. RDNA’s L2 is ~66 ns away from L0, even with a L1 cache between them. Getting around GA102’s massive die seems to take a lot of cycles.
This could explain AMD’s excellent performance at lower resolutions. RDNA 2’s low latency L2 and L3 caches may give it an advantage with smaller workloads, where occupancy is too low to hide latency. Nvidia’s Ampere chips in comparison require more parallelism to shine.
CPUs vs GPUs: It’s a Massacre
CPUs are designed to run serial workloads as fast as possible. GPUs are built to run massively parallel loads. Since the test is written in OpenCL, we can run it unmodified on a CPU.

Haswell’s cache and DRAM latencies are so low that we had to put latency on a logarithmic scale. Otherwise, it’d look like a flat line way below RDNA 2’s figures. The i7-4770 with DDR3-1600 CL9 can do a round trip to memory in 63ns, while a 6900 XT with GDDR6 takes 226 ns to do the same.
From another perspective though, GDDR6 latency itself isn’t so bad. A CPU or GPU has to check cache (and see a miss) before going to memory. So we can get a more “raw” view of memory latency by just looking at how much longer going to memory takes over a last level cache hit. The delta between a last level cache hit and miss is 53.42 ns on Haswell, and 123.2 ns on RDNA2.
As an interesting thought experiment, hypothetical Haswell with GDDR6 memory controllers placed as close to L3 as possible may get somewhere around 133 ns. That’s high for a client CPU, but not so much higher than server memory latency.
Note that from this section and below aren’t comparable with the one above since they’re using a newer version with loop unrolling, and we weren’t able to get a second run on Ampere. However, older Nvidia GPUs like Pascal showed no improvement from a 10x unrolled loop, so there’s a good chance Ampere’s results won’t change.
Older Nvidia GPUs
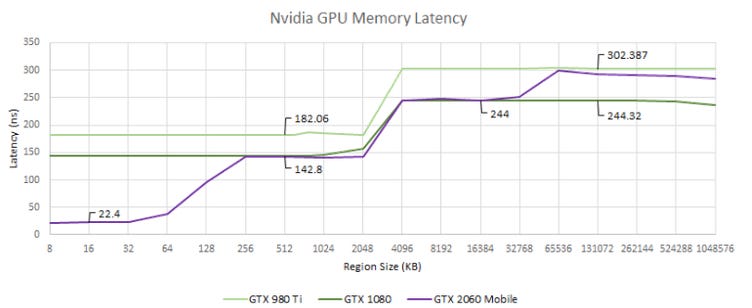
Maxwell and Pascal are largely similar, with the GTX 980 Ti likely suffering due to a larger die and lower clocks. Data just takes longer to get around the chip. Nvidia doesn’t let OpenCL use the L1 texture cache on either architecture, so unfortunately the first thing we see is L2 latency.
Turing starts to look more like Ampere. There’s a relatively low latency L1, then a L2, and finally memory. L2 latency looks roughly in line with Pascal. Raw memory latency looks similar as well up to 32 MB. It’s higher afterwards, but I can’t rule out noise.
Generations of AMD GPUs Compared

I have no explanation for Terascale’s lower latency below 32 KB. AMD says Terascale has a 8 KB L1 data cache, and my results don’t line up. The test might be hitting some kind of vertex reuse cache (since memory loads compile down to vertex fetch clauses).
GCN and RDNA 2 look as expected. And it’s quite interesting to see AMD’s latency at all levels get lower over time.
Hello, thank you for your excellent work. Could you please share the OpenCL code? I've noticed an issue with the latency measured by the program I wrote using ISA instructions. The results are significantly different from yours, and I'm unsure of the cause. Therefore, I would like to refer to and learn from your OpenCL code. If it's possible to share, I would be very grateful.