
Rocket Lake: When ‘Reviews’ are Really Previews

As we’ve all surely seen by now, there are early retail samples in the wild for Intel’s 11th-generation Core desktop CPUs, ‘Rocket Lake-S’, and early reviews to go along with them. Pre-NDA reviews have said good things, bad things and ugly things. What’s not being said (or just not being disclosed) is that they’re running beta firmware and/or not being tested properly.

Author’s Note: Andrei Frumusanu from Anandtech has reached out in this Tweet to clarify how Anandtech does Core to Core latency testing https://twitter.com/andreif7/status/1373942191920406530?s=19
Now, the program we use for Core to Core testing was made by one of our authors, Clamchowder, and can be found here (https://bit.ly/3rbDmFi) or here if you want to compile it yourself (https://github.com/clamchowder/CoherencyLatency)
Now, we don’t know why our Core to Core latency results are approximately double of Anandtech’s however, we are going to make a more in-depth article about core to core latency and comparing different interconnects to each other but it is safe to say that our core to core latency testing will be incomparable to Anandtech’s.
Original Article: I’ve struggled with writing this article because it means poking holes in a review written by someone hugely respected in our community. The fact is though that we can’t know everything and being human means we make mistakes. I’m going to focus on two early takes for Intel’s Rocket Lake-S CPUs. Well, one’s a review, and claims to be.
The other is a “Twitter review”, I suppose. Let’s start there.
CapFrameX’s Flawed Benchmarking
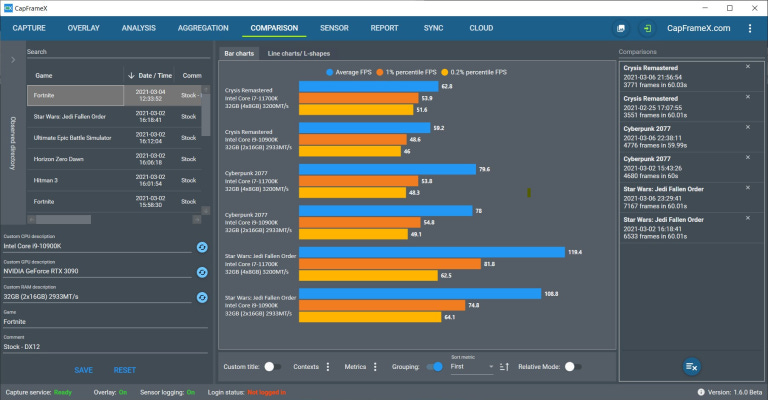
Let’s start with CapFrameX’s thing… This is going to be short. It’s poorly done and deserves to be called out. He tested Comet Lake with 2933 MHz memory in a 2x16GB configuration. The Rocket Lake sample was tested with 3,200 MHz memory in a 4x8GB configuration.
When asked about the timings, he only said it was non-JEDEC. He could have given the Rocket Lake a far faster and more efficient Samsung B-Die kit running at CL14 while Comet Lake got saddled with something like SK Hynix CL18 or 19. This alone can cripple anything memory sensitive on Comet Lake vs Rocket Lake. At a given speed, RAM timings can have a huge impact on effective bandwidth.
Oh oh, many do not agree with the RAM clocks and timings which we used for these benchmarks.
Yes, the timings were not JEDEC compliant. However, the 10900K is specified for 2933MT/s and the 11700K for 3200MT/s. (1/2)
Please note this is not a review, it’s just a quick test to check the general direction. We will offer OC tests and IPC comparisons using the same RAM speed in our review. (2/2)CapFrameX’s justification for mis-matching memory kits in their 11700K testing.
A simple and easy way to compare relative RAM throughput is to take the effective frequency or MT/s and divide by the CAS Latency or CL. This will give you a quick and dirty performance number. 2933 / 19 = 154.37 vs 3200 / 14 = 228.57. In this basic example you are looking at a kit of memory that is possibly 32.5% faster. Yes I say ‘faster’; in simple terms because it will be lower latency and higher bandwidth. If Rocket Lake wasn’t faster than Comet Lake with this handicap, that would be really bad news. Without having the CPUs compared on the same memory kits, the results are invalid. They did however, try to justify the difference between kits with interleaving, missing the point entirely about mix-matching kits and ICs.
I have to clarify an important point here. I forgot to mention this. Sorry!
The Comet Lake system was tested with 2×16 dual ranked DIMMs and the Rocket Lake system with 4×8 single ranked.
Therefore the performance (interleaving) is equivalent.Nope, performance is not equivalent.
A Word on RAM, ICs and Timings
I want to take a second just to address the impact of memory ICs on RAM kit timings. This will be a very high-level pass; Basically, depending on individual IC design, memory chips will skew toward preferring high or low voltage. The differences in their design influence their performance characteristics.
Samsung B-Die is often used in performance-focused memory kits and computer builds simply because it is capable of moving more data at the same frequencies versus its competition—a.k.a faster timings (less cycles/latency)—however it requires more voltage to do so and is notoriously harder to “drive”; It’s harder for IMCs to sustain these loads, and therefore difficult to clock really high. In contrast you have chips like SK Hynix’s DJR, an IC that’s very easy to drive by comparison (less voltage to achieve same clocks). It’s only really good for memory overclocking speed validations, as to achieve the same throughput (clockspeed / latency) as something like Samsung’s B-Die, you’d have to clock it very high as it runs looser timings (more cycles/latency). It often sits at the top of motherboard makers’ memory qualification charts for memory speeds.
With this comparison out of the way, there is one more key factor that needs explaining, and that is what happens when you only set RAM kits to “Auto” or “XMP” and note only primary timings. All motherboards will set secondary, tertiary, and even some hidden timings based on what ICs are detected on the RAM sticks installed. It is imperative that the same memory is then used for benchmarking consistency, as these can have unforeseen effects on performance.
Testing Configuration Hypocrisy
CapFrameX claims he used different memory kits because of the different maximum stock speeds available on the memory controllers for CML-S versus RKL-S; OK Fine. He misses the point however when he adds in the unknown variables coming from different memory kits/ICs. A simple way around all of this would have been to use the same kit on both CPUs, and manually set the speed down to 2,933 MHz from the XMP-rated 3,200 MHz. Then he would have successfully highlighted only the rated speed difference, and you aren’t creating outside factors that can unduly sway your review. A simple reuse of hardware and a change of one setting, would have made for a valid review, in my eyes. Also, taking pot shots at other reviewers for saddling a 9900KS with 2,666 MHz RAM. Whoosh.
Anandtech’s Rocket Lake Review “Blasting Off” Too Early
Update 14/03/21 – A note from the editor: While this article was in the midst of final stages before publishing, Ian and Anandtech released a supplementary article with new CPU Microcode/updated BIOS performance that reflect improved 11700K results since their first article. This just further reinforces our point about pre-release reviews not painting the whole picture. While we believe some concerns were addressed in this follow-up article, the bulk of our concerns around testing consistency with uncore frequency and its affect on total CPU latency/performance remain unaddressed and thus, we felt the need to publish this article still.
Now for the meat and potatoes of this article, and a review written by a well respected and very knowledgeable person: the Intel Core 11700K Review by Dr. Ian Cutress at Anandtech.com.
It bears mentioning that this review was written and published on a motherboard with a beta BIOS, running beta microcodes. I’ve heard there are many issues in the current microcode and BIOSes. [Ed. This has since been (partially) addressed by Ian and Anandtech themselves, as mentioned in the editor’s note above.]
There are numerous ways that poor performance can manifest from early/beta microcode. One of the issues that we’ve heard is the uncore speeds aren’t clocking up like they should. Users can also experience voltages being applied improperly, clocks misbehaving, and numerous other things. I think calling it a review without any large disclaimer(s) about the pre-launch and pre-final nature of the performance is in poor taste. I saw one of his responses saying that any vendor that sends a BIOS 24 hours before NDA lift is shown the door… Cute, completely discounting the weeks before launch that the review is being written. It’s well known that a lot can change between different BIOSes and firmware in 24 hours let alone weeks. The choice he made to publish his review, has in effect made mine to publish this one.
Verifying Uncore/Ring Clock Performance Scaling
I’m focusing on something that I found concerning, and having seen his answer (and lack of response or addressing the follow up) just served to confirm my testing direction.. I had concerns about the uncore or cache/ring clock during his testing of the 11700K. His answer when asked showed an awkward lack of understanding about the way the cache/ring on Intel works. When asked for the uncore frequency in reference to poor L3 latency, he said the L3 latency is fixed on Intel:
L3 is cycles, independent of freq[ency].
Ian Cutress, when asked about the uncore/ring speed, as it affects L3 access times.
Testing Setup
I chose to use a 9900K and a 2x8GB 3,466Mhz CL16-18-18-38 memory kit to test with, as the 9900K is a similar 8C/16T ring bus design Intel CPU. I used Cinebench R23 in 10 minute runs to control for run to run variances. I’ve also used AIDA64 to test for cache and memory throughput and latency. After detailed and intensive testing we now have the basis of our own Core to Core latency tester, that appears to generate similar results to Anandtech’s, primary difference being it appears their results are halved before being put into their charts (at least in reference to our numbers). Beyond the stock run, I set the CPU to an all-core frequency of 5000 MHz. I then varied the uncore from 3000 – 5000 MHz.
Please note that the motherboard that was used for this testing is a Gigabyte Z170X SOC Force LN2 with a custom BIOS that allows for Coffee Lake and Coffee Lake Refresh compatibility. Now, we do recognize that this is an unconventional setup for a 9900K, so we had another user verify the scaling on a Z370.
First up, a quick comparison using Cinebench and AIDA64 to establish that uncore clocks affect performance scaling:
Cinebench R23 Multithreaded Results

AIDA64 L3 Read/Write Bandwidth & Latency Results

AIDA64 L3 Latency Scaling Explored Further
Having established that uncore clocks affect L3 latency, we check performance further in the following screenshots where we take a look at severly hampered (representing potentially buggy scenario) performance at 800 MHz uncore, stock and overclocked at 5000 MHz. Look not at just the latency but also the bandwidth.
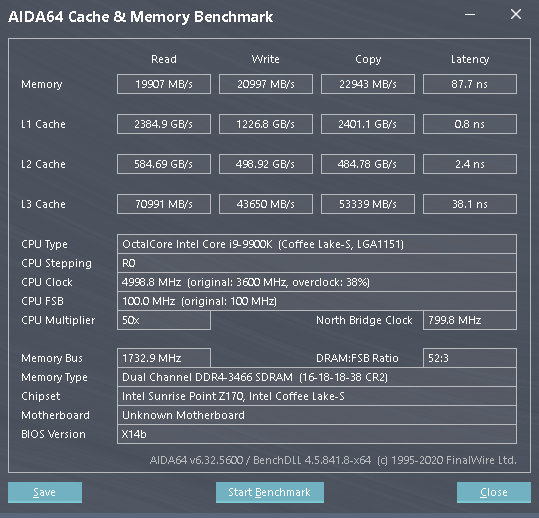
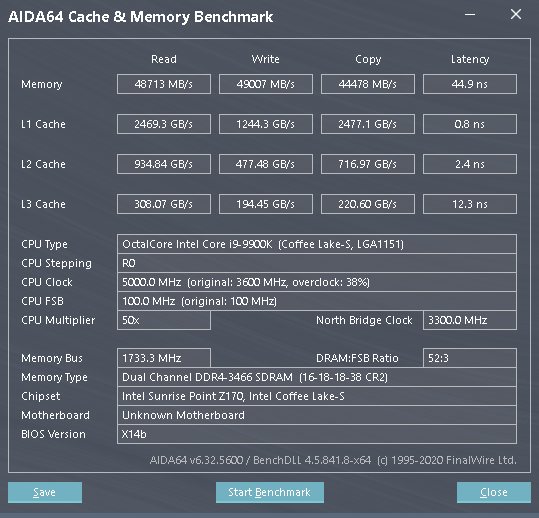
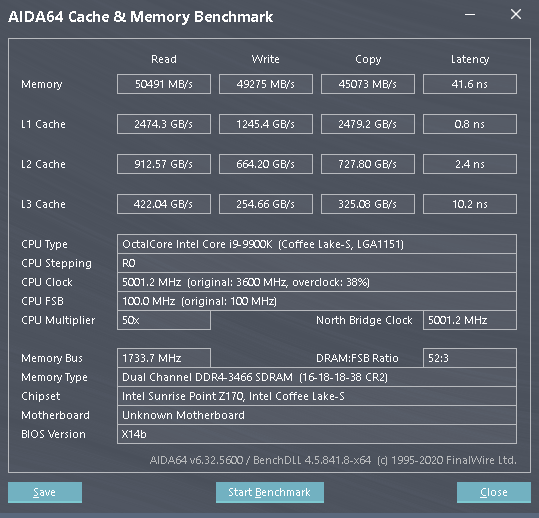
As you can see, low uncore clock hits performance across the board. If it uses the L3 or the memory, performance suffers. Potentially buggy microcode hampering uncore clocks is a cause for concern in Anandtech’s Rocket Lake article that remains unaccounted for. There’s no mention of the uncore, cache or ring clock frequency in the ‘review’ and the perceived lack of understanding of its influence on performance by the author is worrying.
Core-to-Core Latency Scaling with Uncore Clock
Now for our best attempts to recreate the core-to-core latency measurement tool that Anandtech uses. Our tool produces results similar to their tool, except we believe they only present results that have been divided by half. So there will be natural differences as we are providing the raw round trip timing measurement (from core A to core B and back again) whilst Anandtech we believe provide a one-way measurement (from core A to B only, no return).
These tests were done specifically to see if there’s any scaling with the Intel uncore frequency. The results are actually surprising, because Intel has managed to minimize the penalty of crossing clock domains incredibly well. The other takeaway is that core-to-core latency does scale with clockspeed. I have picked a few test results to present as they show all we need. All of the runs are with the all-core clock at 5000 MHz and the uncore frequency set as captioned below (800, 3000, 3600 and 5000).
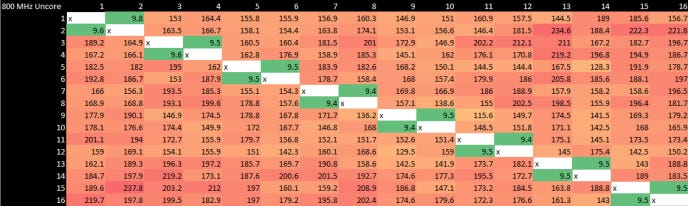
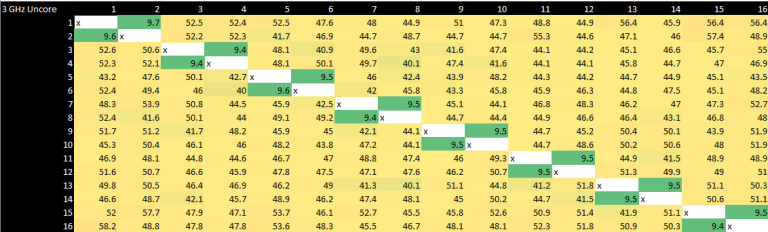
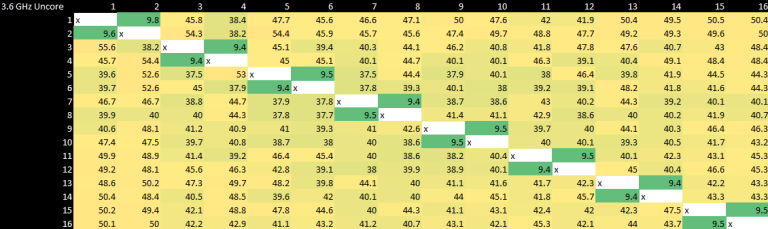
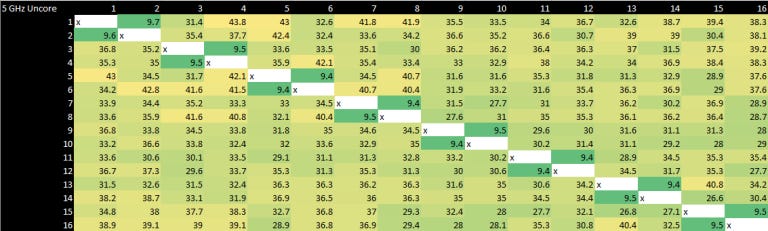
Uncore Importance Understated
These results show quite clearly just how much even a relatively small difference in uncore frequency can affect inter-core latency. This also shows why increasing uncore frequency lowers not just inter-core latency but L3 and system memory latency. If the uncore clocks on the 11700K were being artificially held low, the system would bleed performance.
Another thing I noticed during testing and made note of was that uncore frequency on my 9900K during CB R23 runs didn’t account for a massive power increase. I was watching the system draw on the PSU’s output, and between 3.6 GHz and 5 GHz uncore I saw perhaps 15-20W increased draw at the PSU.
The lack of massive increase in power requirements also points to the possibility that the 11700K could easily have been burning all that power as shown in Anandtech’s review, while still struggling to feed the cores. The good news is that if the uncore clock wasn’t operating properly, it being fixed shouldn’t cause a huge increase in power draw, if Rocket’s cache and ring behave similarly to an 8C Coffee Lake’s.
I believe the testing here has proven that there are real questions to be asked about the lack of clarity in testing. The effects of uncore on system performance have gone misunderstood and understated in all Rocket Lake-S testing done by Anandtech thus far. These are valid concerns as the testing done here (and previously) has laid the connections between uncore and latency bare. Sadly it seems Ian has either missed or chosen to dodge those questions rather than address them.
Too Early to Judge Rocket Lake
Simply put, I have chosen to wait for launch reviews before passing judgment on Intel’s Rocket Lake-S products, and I hope you will as well.
Finally, what bears being said—and perhaps the wider point I am trying to make—is the danger around buying into bombastic hot takes, which has been the trend lately. We all love an underdog story. AMD’s recent resurgence has many enthusiasts in the tech community are all too eagerly awaiting Rocket Lake-S to be a commercial failure as some kind of “karma” for years of Intel feeding us quad core i7s or ~5% IPC increases. I do not believe that Anandtech, Ian, or CapFrameX fall into these camps; however these early preview articles do little to temper the kind of blind bandwagoning happening around anti-Intel bases.
Once there are more sources of information we will be able to make an informed decision. Perhaps the concerns raised here will turn out to be unfounded, or we’ll see Ian & Anandtech having to issue corrections. It may even make sense to take their early ‘review’ down as almost all of the performance data could be found to be flawed. All because of pre-launch software and firmware being used.
All in all, I still say Anandtech and Ian should have called it a preview. Time will tell on March 30th.
 | A guest post by
|